The data volumes generated by theWidefield ASKAP L-band Legacy All-sky Blind surveY atomic hydrogen (Hi) survey using the Australian Square Kilometre Array Pathfinder (ASKAP) necessitate greater automation and reliable automation in the task of source finding and cataloguing. To this end, we introduce and explore a novel deep learning framework for detecting low signal-to-noise ratio (SNR) Hi sources in an automated fashion. Specifically, our proposed method provides an automated process for separating true Hi detections from false positives when used in combination with the source finding application output candidate catalogues. Leveraging the spatial and depth capabilities of 3D convolutional neural networks, our method is specifically designed to recognize patterns and features in three-dimensional space, making it uniquely suited for rejecting false-positive sources in low SNR scenarios generated by conventional linear methods. As a result, our approach is significantly more accurate in source detection and results in considerably fewer false detections compared to previous linear statistics-based source finding algorithms. Performance tests using mock galaxies injected into real ASKAP data cubes reveal our method’s capability to achieve near-100% completeness and reliability at a relatively low integrated SNR 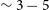 $\sim3-5$. An at-scale version of this tool will greatly maximise the science output from the upcoming widefield Hi surveys.
$\sim3-5$. An at-scale version of this tool will greatly maximise the science output from the upcoming widefield Hi surveys.


