Emerging evidence suggests a co-occurrence of attention-deficit hyperactivity disorder (ADHD) and immune response-related conditions. However, it is unclear whether there is a causal relationship between ADHD and immune response.
We investigated the associations between ADHD traits, common variant genetic liability to ADHD, and serum C-reactive protein (CRP) levels in childhood and adulthood, using data from the Avon Longitudinal Study of Parent and Children. Genetic correlation was estimated using linkage-disequilibrium score regression. Two-sample Mendelian randomization (MR) was conducted to test potential causal effects of ADHD genetic liability on serum CRP as an indicator of systemic inflammation, as well as the genetically proxied levels of specific plasma cytokines.
There was little evidence to suggest association between ADHD and CRP in childhood and adulthood. ADHD genetic liability was associated with a higher serum CRP at ages 9 (β = 0.02, 95% confidence interval [CI] = 0, 0.03), 15 (β = 0.04; 95% CI = 0.02, 0.06), and 24 years (β = 0.03; 95% CI = 0.01, 0.05). There was evidence of genetic correlations between ADHD and CRP ( $ {r}_g $ = 0.27; 95% CI = 0.19, 0.35). Evidence of a bidirectional effect of genetic liability to ADHD and CRP was found by two-sample MR (ADHD-CRP: βIVW= 0.04, 95% CI = 0.01, 0.07; CRP-ADHD: ORIVW = 1.09, 95% CI = 1.01, 1.17).
$ {r}_g $ = 0.27; 95% CI = 0.19, 0.35). Evidence of a bidirectional effect of genetic liability to ADHD and CRP was found by two-sample MR (ADHD-CRP: βIVW= 0.04, 95% CI = 0.01, 0.07; CRP-ADHD: ORIVW = 1.09, 95% CI = 1.01, 1.17).
Further work is necessary to understand the biological pathways linking ADHD genetic liability and CRP and gain insights into understanding how they might contribute in the links between ADHD and later-life adverse physical and mental health outcomes.
Graph-based causal models are a flexible tool for causal inference from observational data. In this paper, we develop a comprehensive framework to define, identify, and estimate a broad class of causal quantities in linearly parametrized graph-based models. The proposed method extends the literature, which mainly focuses on causal effects on the mean level and the variance of an outcome variable. For example, we show how to compute the probability that an outcome variable realizes within a target range of values given an intervention, a causal quantity we refer to as the probability of treatment success. We link graph-based causal quantities defined via the do-operator to parameters of the model implied distribution of the observed variables using so-called causal effect functions. Based on these causal effect functions, we propose estimators for causal quantities and show that these estimators are consistent and converge at a rate of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N^{-1/2}$$\end{document}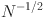 under standard assumptions. Thus, causal quantities can be estimated based on sample sizes that are typically available in the social and behavioral sciences. In case of maximum likelihood estimation, the estimators are asymptotically efficient. We illustrate the proposed method with an example based on empirical data, placing special emphasis on the difference between the interventional and conditional distribution.
under standard assumptions. Thus, causal quantities can be estimated based on sample sizes that are typically available in the social and behavioral sciences. In case of maximum likelihood estimation, the estimators are asymptotically efficient. We illustrate the proposed method with an example based on empirical data, placing special emphasis on the difference between the interventional and conditional distribution.

