
In this article we consider the estimation of the log-normalization constant associated to a class of continuous-time filtering models. In particular, we consider ensemble Kalman–Bucy filter estimates based upon several nonlinear Kalman–Bucy diffusions. Using new conditional bias results for the mean of the aforementioned methods, we analyze the empirical log-scale normalization constants in terms of their 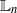 $\mathbb{L}_n$
-errors and
$\mathbb{L}_n$
-errors and 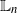 $\mathbb{L}_n$
-conditional bias. Depending on the type of nonlinear Kalman–Bucy diffusion, we show that these are bounded above by terms such as
$\mathbb{L}_n$
-conditional bias. Depending on the type of nonlinear Kalman–Bucy diffusion, we show that these are bounded above by terms such as 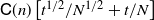 $\mathsf{C}(n)\left[t^{1/2}/N^{1/2} + t/N\right]$
or
$\mathsf{C}(n)\left[t^{1/2}/N^{1/2} + t/N\right]$
or 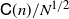 $\mathsf{C}(n)/N^{1/2}$
(
$\mathsf{C}(n)/N^{1/2}$
(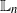 $\mathbb{L}_n$
-errors) and
$\mathbb{L}_n$
-errors) and 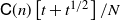 $\mathsf{C}(n)\left[t+t^{1/2}\right]/N$
or
$\mathsf{C}(n)\left[t+t^{1/2}\right]/N$
or 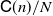 $\mathsf{C}(n)/N$
(
$\mathsf{C}(n)/N$
(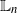 $\mathbb{L}_n$
-conditional bias), where t is the time horizon, N is the ensemble size, and
$\mathbb{L}_n$
-conditional bias), where t is the time horizon, N is the ensemble size, and 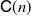 $\mathsf{C}(n)$
is a constant that depends only on n, not on N or t. Finally, we use these results for online static parameter estimation for the above filtering models and implement the methodology for both linear and nonlinear models.
$\mathsf{C}(n)$
is a constant that depends only on n, not on N or t. Finally, we use these results for online static parameter estimation for the above filtering models and implement the methodology for both linear and nonlinear models.

