
We study the problem of identifying a small number 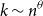 $k\sim n^\theta$,
$k\sim n^\theta$, 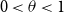 $0\lt \theta \lt 1$, of infected individuals within a large population of size
$0\lt \theta \lt 1$, of infected individuals within a large population of size  $n$ by testing groups of individuals simultaneously. All tests are conducted concurrently. The goal is to minimise the total number of tests required. In this paper, we make the (realistic) assumption that tests are noisy, that is, that a group that contains an infected individual may return a negative test result or one that does not contain an infected individual may return a positive test result with a certain probability. The noise need not be symmetric. We develop an algorithm called SPARC that correctly identifies the set of infected individuals up to
$n$ by testing groups of individuals simultaneously. All tests are conducted concurrently. The goal is to minimise the total number of tests required. In this paper, we make the (realistic) assumption that tests are noisy, that is, that a group that contains an infected individual may return a negative test result or one that does not contain an infected individual may return a positive test result with a certain probability. The noise need not be symmetric. We develop an algorithm called SPARC that correctly identifies the set of infected individuals up to 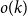 $o(k)$ errors with high probability with the asymptotically minimum number of tests. Additionally, we develop an algorithm called SPEX that exactly identifies the set of infected individuals w.h.p. with a number of tests that match the information-theoretic lower bound for the constant column design, a powerful and well-studied test design.
$o(k)$ errors with high probability with the asymptotically minimum number of tests. Additionally, we develop an algorithm called SPEX that exactly identifies the set of infected individuals w.h.p. with a number of tests that match the information-theoretic lower bound for the constant column design, a powerful and well-studied test design.



