Static analysis of logic programs by abstract interpretation requires designing abstract operators which mimic the concrete ones, such as unification, renaming, and projection. In the case of goal-driven analysis, where goal-dependent semantics are used, we also need a backward-unification operator, typically implemented through matching. In this paper, we study the problem of deriving optimal abstract matching operators for sharing and linearity properties. We provide an optimal operator for matching in the domain  $\mathtt{ShLin}^{\omega }$, which can be easily instantiated to derive optimal operators for the domains
$\mathtt{ShLin}^{\omega }$, which can be easily instantiated to derive optimal operators for the domains  $\mathtt{ShLin}^2$ by Andy King and the reduced product
$\mathtt{ShLin}^2$ by Andy King and the reduced product  $\mathtt{Sharing} \times \mathtt{Lin}$.
$\mathtt{Sharing} \times \mathtt{Lin}$.
In this paper, we analyze two types of refutations for Unit Two Variable Per Inequality (UTVPI) constraints. A UTVPI constraint is a linear inequality of the form: 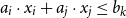 $a_{i}\cdot x_{i}+a_{j} \cdot x_{j} \le b_{k}$, where
$a_{i}\cdot x_{i}+a_{j} \cdot x_{j} \le b_{k}$, where 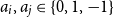 $a_{i},a_{j}\in \{0,1,-1\}$ and
$a_{i},a_{j}\in \{0,1,-1\}$ and 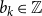 $b_{k} \in \mathbb{Z}$. A conjunction of such constraints is called a UTVPI constraint system (UCS) and can be represented in matrix form as:
$b_{k} \in \mathbb{Z}$. A conjunction of such constraints is called a UTVPI constraint system (UCS) and can be represented in matrix form as: 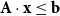 ${\bf A \cdot x \le b}$. UTVPI constraints are used in many domains including operations research and program verification. We focus on two variants of read-once refutation (ROR). An ROR is a refutation in which each constraint is used at most once. A literal-once refutation (LOR), a more restrictive form of ROR, is a refutation in which each literal (
${\bf A \cdot x \le b}$. UTVPI constraints are used in many domains including operations research and program verification. We focus on two variants of read-once refutation (ROR). An ROR is a refutation in which each constraint is used at most once. A literal-once refutation (LOR), a more restrictive form of ROR, is a refutation in which each literal (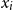 $x_i$ or
$x_i$ or 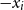 $-x_i$) is used at most once. First, we examine the constraint-required read-once refutation (CROR) problem and the constraint-required literal-once refutation (CLOR) problem. In both of these problems, we are given a set of constraints that must be used in the refutation. RORs and LORs are incomplete since not every system of linear constraints is guaranteed to have such a refutation. This is still true even when we restrict ourselves to UCSs. In this paper, we provide NC reductions between the CROR and CLOR problems in UCSs and the minimum weight perfect matching problem. The reductions used in this paper assume a CREW PRAM model of parallel computation. As a result, the reductions establish that, from the perspective of parallel algorithms, the CROR and CLOR problems in UCSs are equivalent to matching. In particular, if an NC algorithm exists for either of these problems, then there is an NC algorithm for matching.
$-x_i$) is used at most once. First, we examine the constraint-required read-once refutation (CROR) problem and the constraint-required literal-once refutation (CLOR) problem. In both of these problems, we are given a set of constraints that must be used in the refutation. RORs and LORs are incomplete since not every system of linear constraints is guaranteed to have such a refutation. This is still true even when we restrict ourselves to UCSs. In this paper, we provide NC reductions between the CROR and CLOR problems in UCSs and the minimum weight perfect matching problem. The reductions used in this paper assume a CREW PRAM model of parallel computation. As a result, the reductions establish that, from the perspective of parallel algorithms, the CROR and CLOR problems in UCSs are equivalent to matching. In particular, if an NC algorithm exists for either of these problems, then there is an NC algorithm for matching.

