Optimal transport tasks naturally arise in gas networks, which include a variety of constraints such as physical plausibility of the transport and the avoidance of extreme pressure fluctuations. To define feasible optimal transport plans, we utilize a  $p$-Wasserstein metric and similar dynamic formulations minimizing the kinetic energy necessary for moving gas through the network, which we combine with suitable versions of Kirchhoff’s law as the coupling condition at nodes. In contrast to existing literature, we especially focus on the non-standard case
$p$-Wasserstein metric and similar dynamic formulations minimizing the kinetic energy necessary for moving gas through the network, which we combine with suitable versions of Kirchhoff’s law as the coupling condition at nodes. In contrast to existing literature, we especially focus on the non-standard case  $p \neq 2$ to derive an overdamped isothermal model for gases through
$p \neq 2$ to derive an overdamped isothermal model for gases through  $p$-Wasserstein gradient flows in order to uncover and analyze underlying dynamics. We introduce different options for modelling the gas network as an oriented graph including the possibility to store gas at interior vertices and to put in or take out gas at boundary vertices.
$p$-Wasserstein gradient flows in order to uncover and analyze underlying dynamics. We introduce different options for modelling the gas network as an oriented graph including the possibility to store gas at interior vertices and to put in or take out gas at boundary vertices.
We establish that the existence of a winning strategy in certain topological games, closely related to a strong game of Choquet, played in a topological space 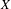 $X$ and its hyperspace
$X$ and its hyperspace 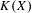 $K(X)$ of all nonempty compact subsets of
$K(X)$ of all nonempty compact subsets of 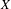 $X$ equipped with the Vietoris topology, is equivalent for one of the players. For a separable metrizable space
$X$ equipped with the Vietoris topology, is equivalent for one of the players. For a separable metrizable space 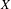 $X$, we identify a game-theoretic condition equivalent to
$X$, we identify a game-theoretic condition equivalent to 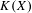 $K(X)$ being hereditarily Baire. It implies quite easily a recent result of Gartside, Medini and Zdomskyy that characterizes hereditary Baire property of hyperspaces
$K(X)$ being hereditarily Baire. It implies quite easily a recent result of Gartside, Medini and Zdomskyy that characterizes hereditary Baire property of hyperspaces 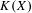 $K(X)$ over separable metrizable spaces
$K(X)$ over separable metrizable spaces 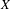 $X$ via the Menger property of the remainder of a compactification of
$X$ via the Menger property of the remainder of a compactification of 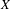 $X$. Subsequently, we use topological games to study hereditary Baire property in spaces of probability measures and in hyperspaces over filters on natural numbers. To this end, we introduce a notion of strong
$X$. Subsequently, we use topological games to study hereditary Baire property in spaces of probability measures and in hyperspaces over filters on natural numbers. To this end, we introduce a notion of strong  $P$-filter
$P$-filter 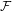 ${\mathcal{F}}$ and prove that it is equivalent to
${\mathcal{F}}$ and prove that it is equivalent to 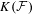 $K({\mathcal{F}})$ being hereditarily Baire. We also show that if
$K({\mathcal{F}})$ being hereditarily Baire. We also show that if 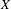 $X$ is separable metrizable and
$X$ is separable metrizable and 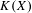 $K(X)$ is hereditarily Baire, then the space
$K(X)$ is hereditarily Baire, then the space 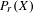 $P_{r}(X)$ of Borel probability Radon measures on
$P_{r}(X)$ of Borel probability Radon measures on 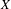 $X$ is hereditarily Baire too. It follows that there exists (in ZFC) a separable metrizable space
$X$ is hereditarily Baire too. It follows that there exists (in ZFC) a separable metrizable space 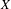 $X$, which is not completely metrizable with
$X$, which is not completely metrizable with 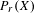 $P_{r}(X)$ hereditarily Baire. As far as we know, this is the first example of this kind.
$P_{r}(X)$ hereditarily Baire. As far as we know, this is the first example of this kind.
We study Smale skew product endomorphisms (introduced in Mihailescu and Urbański [Skew product Smale endomorphisms over countable shifts of finite type. Ergod. Th. & Dynam. Sys. doi: 10.1017/etds.2019.31. Published online June 2019]) now over countable graph-directed Markov systems, and we prove the exact dimensionality of conditional measures in fibers, and then the global exact dimensionality of the equilibrium measure itself. Our results apply to large classes of systems and have many applications. They apply, for instance, to natural extensions of graph-directed Markov systems. Another application is to skew products over parabolic systems. We also give applications in ergodic number theory, for example to the continued fraction expansion, and the backward fraction expansion. In the end we obtain a general formula for the Hausdorff (and pointwise) dimension of equilibrium measures with respect to the induced maps of natural extensions  ${\mathcal{T}}_{\unicode[STIX]{x1D6FD}}$ of
${\mathcal{T}}_{\unicode[STIX]{x1D6FD}}$ of 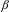 $\unicode[STIX]{x1D6FD}$-maps
$\unicode[STIX]{x1D6FD}$-maps 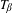 $T_{\unicode[STIX]{x1D6FD}}$, for arbitrary
$T_{\unicode[STIX]{x1D6FD}}$, for arbitrary 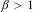 $\unicode[STIX]{x1D6FD}>1$.
$\unicode[STIX]{x1D6FD}>1$.
Let 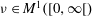 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\nu \in M^1([0,\infty [)$ be a fixed probability measure. For each dimension
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\nu \in M^1([0,\infty [)$ be a fixed probability measure. For each dimension 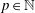 $p\in \mathbb{N}$, let
$p\in \mathbb{N}$, let 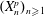 $(X_n^{p})_{n\geq 1}$ be independent and identically distributed
$(X_n^{p})_{n\geq 1}$ be independent and identically distributed 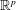 $\mathbb{R}^p$-valued random variables with radially symmetric distributions and radial distribution
$\mathbb{R}^p$-valued random variables with radially symmetric distributions and radial distribution  $\nu $. We investigate the distribution of the Euclidean length of
$\nu $. We investigate the distribution of the Euclidean length of 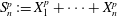 $S_n^{p}:=X_1^{p}+\cdots + X_n^{p}$ for large parameters
$S_n^{p}:=X_1^{p}+\cdots + X_n^{p}$ for large parameters  $n$ and
$n$ and 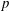 $p$. Depending on the growth of the dimension
$p$. Depending on the growth of the dimension  $p=p_n$ we derive by the method of moments two complementary central limit theorems (CLTs) for the functional
$p=p_n$ we derive by the method of moments two complementary central limit theorems (CLTs) for the functional 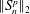 $\| S_n^{p}\| _2$ with normal limits, namely for
$\| S_n^{p}\| _2$ with normal limits, namely for 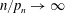 $n/p_n \to \infty $ and
$n/p_n \to \infty $ and 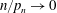 $n/p_n \to 0$. Moreover, we present a CLT for the case
$n/p_n \to 0$. Moreover, we present a CLT for the case 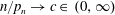 $n/p_n \to c\in \, (0,\infty )$. Thereby we derive explicit formulas and asymptotic results for moments of radial distributed random variables on
$n/p_n \to c\in \, (0,\infty )$. Thereby we derive explicit formulas and asymptotic results for moments of radial distributed random variables on 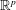 $\mathbb{R}^p$. All limit theorems are also considered for orthogonal invariant random walks on the space
$\mathbb{R}^p$. All limit theorems are also considered for orthogonal invariant random walks on the space 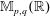 $\mathbb{M}_{p,q}(\mathbb{R})$ of
$\mathbb{M}_{p,q}(\mathbb{R})$ of 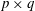 $p\times q$ matrices instead of
$p\times q$ matrices instead of 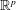 $\mathbb{R}^p$ for
$\mathbb{R}^p$ for 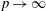 $p\to \infty $ and some fixed dimension
$p\to \infty $ and some fixed dimension 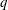 $q$.
$q$.
We consider a class of fractal subsets of
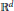 ${{\mathbb{R}}^{d}}$
formed in a manner analogous to the construction of the Sierpinski carpet. We prove a uniform Harnack inequality for positive harmonic functions; study the heat equation, and obtain upper and lower bounds on the heat kernel which are, up to constants, the best possible; construct a locally isotropic diffusion
${{\mathbb{R}}^{d}}$
formed in a manner analogous to the construction of the Sierpinski carpet. We prove a uniform Harnack inequality for positive harmonic functions; study the heat equation, and obtain upper and lower bounds on the heat kernel which are, up to constants, the best possible; construct a locally isotropic diffusion 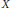 $X$ and determine its basic properties; and extend some classical Sobolev and Poincaré inequalities to this setting.
$X$ and determine its basic properties; and extend some classical Sobolev and Poincaré inequalities to this setting.

