



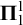
1 Introduction
A common scenario in algorithmic learning theory can be viewed in terms of the following game played in infinitely many stages:
Fix a countable sequence of languages
 $(l_i)_{i\in \omega }$
,
$(l_i)_{i\in \omega }$
,
 $l_i\subseteq \omega $
(possibly with repetitions) and an index
$l_i\subseteq \omega $
(possibly with repetitions) and an index
 $i_0$
. At each stage s, an informant presents a learner with a word
$i_0$
. At each stage s, an informant presents a learner with a word
 $w_s\in l_{i_0}$
such that
$w_s\in l_{i_0}$
such that
 $\{w_s: s\in \omega \}=l_{i_0}$
and the learner has to make a hypothesis
$\{w_s: s\in \omega \}=l_{i_0}$
and the learner has to make a hypothesis
 $h_s\in \omega $
, guessing which language they are presented with.
$h_s\in \omega $
, guessing which language they are presented with.
This way of presenting the language
 $l_{i_0}$
is often referred to as learning from text. There are several ways to define winning conditions for this learning game. The first one, giving the learning paradigm often referred to as explanatory learning or learning in the limit is due to Gold [Reference Gold8]:
$l_{i_0}$
is often referred to as learning from text. There are several ways to define winning conditions for this learning game. The first one, giving the learning paradigm often referred to as explanatory learning or learning in the limit is due to Gold [Reference Gold8]:
The learner wins the game if after finitely many stages they stabilize on a correct hypothesis, i.e., if there exists
 $h=\lim _s h_s$
and
$h=\lim _s h_s$
and
 $l_h=l_{i_0}$
.
$l_h=l_{i_0}$
.
Another learning paradigm, behaviourally correct (BC) learning, is due to Feldman [Reference Feldman6]:
The learner wins the game if there is a finite stage s such that at all stages
 $t>s$
,
$t>s$
,
 $l_{h_t}=l_{i_0}$
.
$l_{h_t}=l_{i_0}$
.
Notice that we do not require that the learner guesses the correct index, they just need to identify the language up to equality.
Recently, Fokina, Kötzing, and San Mauro [Reference Fokina, Kötzing and Mauro7] adapted the explanatory paradigm to learning of the isomorphism relation on countable structures. As above, we can view this as a game where a sequence of countable structures
 $(\mathcal {A}_i)_{i\in \omega }$
is fixed, and the learner, presented with finite fragments of a structure
$(\mathcal {A}_i)_{i\in \omega }$
is fixed, and the learner, presented with finite fragments of a structure
 $\mathcal {B}$
, needs to hypothesize to which of the
$\mathcal {B}$
, needs to hypothesize to which of the
 $\mathcal {A}_i \mathcal {B}$
is isomorphic. The difference to classical explanatory learning is that the informant may play an isomorphic copy of one of the structures
$\mathcal {A}_i \mathcal {B}$
is isomorphic. The difference to classical explanatory learning is that the informant may play an isomorphic copy of one of the structures
 $\mathcal {A}_i$
, or a structure not isomorphic to any of the structures in the sequence. Bazhenov, Fokina, and San Mauro [Reference Bazhenov, Fokina and Mauro3] characterized learnable sequences of structures as those that have
$\mathcal {A}_i$
, or a structure not isomorphic to any of the structures in the sequence. Bazhenov, Fokina, and San Mauro [Reference Bazhenov, Fokina and Mauro3] characterized learnable sequences of structures as those that have
 $\Sigma ^{\mathrm {in}}_{2}$
quasi Scott sentences in the infinitary logic
$\Sigma ^{\mathrm {in}}_{2}$
quasi Scott sentences in the infinitary logic
 $L_{\omega _1\omega }$
. That is, sentences
$L_{\omega _1\omega }$
. That is, sentences
 ${\varphi }_i$
of the form
${\varphi }_i$
of the form
 $\mathop { \mathchoice {\bigvee \mkern -15mu\bigvee } {\bigvee \mkern -12.5mu\bigvee } {\bigvee \mkern -12.5mu\bigvee } {\bigvee \mkern -11mu\bigvee } } _{i\in \omega } \exists \bar x \mathop { \mathchoice {\bigwedge \mkern -15mu\bigwedge } {\bigwedge \mkern -12.5mu\bigwedge } {\bigwedge \mkern -12.5mu\bigwedge } {\bigwedge \mkern -11mu\bigwedge } } _{j\in \omega } \forall \bar y \psi _{i,j}(\bar x,\bar y)$
where the
$\mathop { \mathchoice {\bigvee \mkern -15mu\bigvee } {\bigvee \mkern -12.5mu\bigvee } {\bigvee \mkern -12.5mu\bigvee } {\bigvee \mkern -11mu\bigvee } } _{i\in \omega } \exists \bar x \mathop { \mathchoice {\bigwedge \mkern -15mu\bigwedge } {\bigwedge \mkern -12.5mu\bigwedge } {\bigwedge \mkern -12.5mu\bigwedge } {\bigwedge \mkern -11mu\bigwedge } } _{j\in \omega } \forall \bar y \psi _{i,j}(\bar x,\bar y)$
where the
 $\psi _{i,j}$
are quantifier-free such that
$\psi _{i,j}$
are quantifier-free such that
 $\mathcal {A}_i\models {\varphi }_i$
and if
$\mathcal {A}_i\models {\varphi }_i$
and if
 $\mathcal {A}_j\not \cong \mathcal {A}_i$
, then
$\mathcal {A}_j\not \cong \mathcal {A}_i$
, then
 $\mathcal {A}_j\not \models {\varphi }_i$
. A result connecting this paradigm with descriptive set theory is due to Bazhenov, Cipriani, and San Mauro [Reference Bazhenov, Cipriani and Mauro2]. They showed that a sequence of structures is learnable if and only if the isomorphism problem on the associated class is continuously reducible to
$\mathcal {A}_j\not \models {\varphi }_i$
. A result connecting this paradigm with descriptive set theory is due to Bazhenov, Cipriani, and San Mauro [Reference Bazhenov, Cipriani and Mauro2]. They showed that a sequence of structures is learnable if and only if the isomorphism problem on the associated class is continuously reducible to
 $E_0$
, the eventual equality relation on infinite binary strings.
$E_0$
, the eventual equality relation on infinite binary strings.
Motivated by the above work, we take a different approach to connecting algorithmic learning theory with descriptive set theory. Our aim is to study the following question:
What does it mean for an equivalence relation on a Polish space to be learnable?
Fokina, Kötzing, and San Mauro’s learning paradigm already gives some insight into an equivalence relation on a Polish space. After all, the space of countable structures in a relational vocabulary can be viewed as a closed subspace of
 $2^\omega $
and thus admits a natural Polish topology. However, learnability in their paradigm is a local property, only giving information on the countable set of isomorphism classes obtained from the sequence
$2^\omega $
and thus admits a natural Polish topology. However, learnability in their paradigm is a local property, only giving information on the countable set of isomorphism classes obtained from the sequence
 $(\mathcal {A}_i)_{i\in \omega }$
.
$(\mathcal {A}_i)_{i\in \omega }$
.
Our approach is global, aiming to give information into an equivalence relation on the whole space. We introduce and study both uniform and non-uniform versions of explanatory learning and behaviourally correct learning of equivalence relations on Polish spaces. Our main results show that both the uniform and non-uniform versions of these learning paradigms are equivalent (Theorems 2 and 11). The proof of this result for the non-uniform version is relatively simple, while the proof of the uniform result is quite involved, using recent results of Lecomte [Reference Lecomte13] on Borel equivalence relations and one of our other main theorems, that an equivalence relation is uniformly (explanatory) learnable if and only if it is
 $\boldsymbol {\Sigma }^0_2$
. All of the above results are covered in Section 2.
$\boldsymbol {\Sigma }^0_2$
. All of the above results are covered in Section 2.
In Section 3 we show that the complexity of the set of learnable
 $\boldsymbol {\Pi }^0_2$
equivalence relations on
$\boldsymbol {\Pi }^0_2$
equivalence relations on
 $2^\omega $
is
$2^\omega $
is
 $\boldsymbol {\Pi }^1_1$
-complete in the codes. In Section 4 we analyse the learnability of various equivalence relations that arise naturally in computability and model theory. At last, we give an example of a natural
$\boldsymbol {\Pi }^1_1$
-complete in the codes. In Section 4 we analyse the learnability of various equivalence relations that arise naturally in computability and model theory. At last, we give an example of a natural
 $\Pi ^1_1$
subset of the natural numbers that is neither
$\Pi ^1_1$
subset of the natural numbers that is neither
 $\Sigma ^1_1$
nor
$\Sigma ^1_1$
nor
 $\Pi ^1_1$
-complete.
$\Pi ^1_1$
-complete.
The proofs of our results use techniques from several areas of mathematical logic. Our results in Section 2 rely on Cohen forcing and results in the theory of Borel equivalence relations, in Section 3 we use techniques from higher recursion theory and effective descriptive set theory, and most proofs in Section 4 will seem familiar to computability theorists. We assume that the reader has some familiarity with these subjects.
All our proofs are written assuming that the underlying Polish space is Cantor space
 $2^\omega $
—the space of infinite binary strings (or sequences) under the product topology. However, the theorems are stated for general (effective) Polish spaces. Our proofs can be easily modified to hold in this setting.
$2^\omega $
—the space of infinite binary strings (or sequences) under the product topology. However, the theorems are stated for general (effective) Polish spaces. Our proofs can be easily modified to hold in this setting.
2 Notions of learnability
2.1 Non-uniform learnability
The following definition presents our attempt to obtain a non-uniform generalization of the explanatory learning framework. We adopt the following notational convention: if
 $\vec x$
is used to denote a sequence, then
$\vec x$
is used to denote a sequence, then
 $x_i$
denotes its ith column, i.e.,
$x_i$
denotes its ith column, i.e.,
 $\vec x = (x_i)_{i\in \omega }$
. If x is used to denote a sequence, then
$\vec x = (x_i)_{i\in \omega }$
. If x is used to denote a sequence, then
 $x(i)$
means its ith element. If
$x(i)$
means its ith element. If
 $\vec y$
is a sequence of infinite strings and x is an infinite string, we write
$\vec y$
is a sequence of infinite strings and x is an infinite string, we write
 $x^\smallfrown \vec y$
to denote
$x^\smallfrown \vec y$
to denote
 $(y,x_0,x_1,\ldots )$
$(y,x_0,x_1,\ldots )$
Definition 1. Let E be an equivalence relation on a Polish space X and assume
 $\omega $
is equipped with the discrete topology. We say that E is non-uniformly learnable if for every
$\omega $
is equipped with the discrete topology. We say that E is non-uniformly learnable if for every
 $\vec x\in X^{\omega }$
, there are continuous functions
$\vec x\in X^{\omega }$
, there are continuous functions
 $l_n(\vec x): X\to \omega $
such that for every
$l_n(\vec x): X\to \omega $
such that for every
 $x\in X$
, if
$x\in X$
, if
 $xEx_i$
for some
$xEx_i$
for some
 $i\in \omega $
, then
$i\in \omega $
, then
 $L(x,\vec x)=\lim l_n( \vec x,x)$
exists and
$L(x,\vec x)=\lim l_n( \vec x,x)$
exists and
 $x E x_{L(x,\vec x)}$
. We call the partial function L a learner, and write
$x E x_{L(x,\vec x)}$
. We call the partial function L a learner, and write
 $L(x,\vec x,n)$
for
$L(x,\vec x,n)$
for
 $l_n(\vec x,x)$
.
$l_n(\vec x,x)$
.
If
 $x\not\!\! {\mathrel {E}} x_i$
for any
$x\not\!\! {\mathrel {E}} x_i$
for any
 $x_i\in \vec x$
, then the behavior of a potential learner L is not specified. It might not be defined, or its value might be any index. We say that a learner L which is defined in this case gives false positives. The following result is reminiscent of a characterization of explanatory learning of structures given in [Reference Bazhenov, Fokina and Mauro3].
$x_i\in \vec x$
, then the behavior of a potential learner L is not specified. It might not be defined, or its value might be any index. We say that a learner L which is defined in this case gives false positives. The following result is reminiscent of a characterization of explanatory learning of structures given in [Reference Bazhenov, Fokina and Mauro3].
Proposition 1. Let
 $\mathrel {E}$
be an equivalence relation on a Polish space X. Then the following are equivalent.
$\mathrel {E}$
be an equivalence relation on a Polish space X. Then the following are equivalent.
-
(1)
 $\mathrel {E}$
is non-uniformly learnable.
$\mathrel {E}$
is non-uniformly learnable. -
(2) For every
$\vec x\in X^\omega $
, there are sets
$S_i\in \boldsymbol {\Sigma }^0_2(X)$
such that for every
$i\in \omega $
,
$[x_i]_{E}\subseteq S_i$
and
$S_i\cap S_j=\emptyset $
if
$x_i\not\!\! {\mathrel {E}} x_j$
.







Furthermore,
 $\mathrel {E}$
is non-uniformly learnable by learners not giving false positives if and only if
$\mathrel {E}$
is non-uniformly learnable by learners not giving false positives if and only if
 $[x]_{E}$
is
$[x]_{E}$
is
 $\boldsymbol {\Sigma }^0_2$
for every
$\boldsymbol {\Sigma }^0_2$
for every
 $x\in X$
.
$x\in X$
.
Proof. (2)
 $\implies $
(1). Given
$\implies $
(1). Given
 $\vec x$
, let
$\vec x$
, let
 $(S_i)_{i\in \omega }$
be a countable sequence of
$(S_i)_{i\in \omega }$
be a countable sequence of
 $\Sigma ^0_2(p_i)$
sets covering
$\Sigma ^0_2(p_i)$
sets covering
 $[x_i]_{E}$
such that if
$[x_i]_{E}$
such that if
 $x_i\not\!\! {\mathrel {E}} x_j$
, then
$x_i\not\!\! {\mathrel {E}} x_j$
, then
 $S_i\cap S_j=\emptyset $
and let
$S_i\cap S_j=\emptyset $
and let
 $(R_i)_{i\in \omega }$
be recursive relations such that
$(R_i)_{i\in \omega }$
be recursive relations such that
 $$\begin{align*}x\in S_i\iff \exists n\forall m\ R_i(x,p_i,n,m).\end{align*}$$
$$\begin{align*}x\in S_i\iff \exists n\forall m\ R_i(x,p_i,n,m).\end{align*}$$
Then, for any
 $x\in X$
and
$x\in X$
and
 $s\in \omega $
define
$s\in \omega $
define
 $L(x,\vec x,s)$
to be the minimal
$L(x,\vec x,s)$
to be the minimal
 $i<s$
such that for some
$i<s$
such that for some
 $n<s$
and all
$n<s$
and all
 $m<s$
,
$m<s$
,
 $R_i(x,p_i,n,m)$
holds, if such i exists and
$R_i(x,p_i,n,m)$
holds, if such i exists and
 $L(x,\vec x,s)=s$
, otherwise. From the disjointness of the
$L(x,\vec x,s)=s$
, otherwise. From the disjointness of the
 $S_i$
we get that if j is least such that
$S_i$
we get that if j is least such that
 $x\mathrel {E} x_j$
, then
$x\mathrel {E} x_j$
, then
 $L(x,\vec x)=j$
. Also, for every s, the function
$L(x,\vec x)=j$
. Also, for every s, the function
 $L(-,\vec x,s)$
is recursive in
$L(-,\vec x,s)$
is recursive in
 $\bigoplus p_i$
and hence continuous. Thus, L is a learner learning
$\bigoplus p_i$
and hence continuous. Thus, L is a learner learning
 $\vec x$
with respect to
$\vec x$
with respect to
 $\mathrel {E}$
. Furthermore, if
$\mathrel {E}$
. Furthermore, if
 $[x]_E$
is
$[x]_E$
is
 $\boldsymbol {\Sigma }^0_2$
for every
$\boldsymbol {\Sigma }^0_2$
for every
 $x\in X $
, then we may assume in the above proof that
$x\in X $
, then we may assume in the above proof that
 $S_i=[x_i]_E$
. In that case, for fixed x such that for every i,
$S_i=[x_i]_E$
. In that case, for fixed x such that for every i,
 $x\not \in [x_i]_E$
,
$x\not \in [x_i]_E$
,
 $L(x,\vec x)\uparrow $
and thus L does not give false positives.
$L(x,\vec x)\uparrow $
and thus L does not give false positives.
(1)
 $\implies $
(2). Let L be a learner for
$\implies $
(2). Let L be a learner for
 $\vec x$
and note that for all i the sets
$\vec x$
and note that for all i the sets
 $L(x,\vec x,n)^{-1}(i)$
are clopen. Then let
$L(x,\vec x,n)^{-1}(i)$
are clopen. Then let
 $C_{n,i}=\{x: (\forall m>n) L(x,\vec x,m)= i\}$
, define
$C_{n,i}=\{x: (\forall m>n) L(x,\vec x,m)= i\}$
, define
 $D_i =\bigcup _n C_{n,i}$
and
$D_i =\bigcup _n C_{n,i}$
and
 $S_i=\bigcup _{x_i\mathrel {E} x_j} D_j$
. Then the
$S_i=\bigcup _{x_i\mathrel {E} x_j} D_j$
. Then the
 $S_i$
are
$S_i$
are
 $\boldsymbol {\Sigma }^0_2$
and by the definition of non-uniform learnability
$\boldsymbol {\Sigma }^0_2$
and by the definition of non-uniform learnability
 $[x_i]_E\subseteq S_i$
. If L learns
$[x_i]_E\subseteq S_i$
. If L learns
 $\vec x$
without giving false positives, then clearly
$\vec x$
without giving false positives, then clearly
 $S_i=[x_i]_E$
.
$S_i=[x_i]_E$
.
We now turn our attention to a non-uniform adaptation of behaviorally correct learning.
Definition 2. Let
 $ \mathrel {E}$
be an equivalence relation on a Polish space X and assume
$ \mathrel {E}$
be an equivalence relation on a Polish space X and assume
 $\omega $
is equipped with the discrete topology. We say that
$\omega $
is equipped with the discrete topology. We say that
 $\mathrel {E}$
is non-uniformly
$\mathrel {E}$
is non-uniformly
 $\mathsf {BC}$
-learnable if for every
$\mathsf {BC}$
-learnable if for every
 $\vec x=(x_i)_{i\in \omega }\in X^\omega $
there are continuous functions
$\vec x=(x_i)_{i\in \omega }\in X^\omega $
there are continuous functions
 $l_n: X^\omega \times X\to \omega $
such that for
$l_n: X^\omega \times X\to \omega $
such that for
 $x\in X$
, if
$x\in X$
, if
 $x\mathrel {E} x_i$
for some
$x\mathrel {E} x_i$
for some
 $i\in \omega $
, then for almost every n,
$i\in \omega $
, then for almost every n,
 $x\mathrel {E} x_{l_n(\vec x, x)}$
.
$x\mathrel {E} x_{l_n(\vec x, x)}$
.
The observant reader might immediately notice that non-uniform
 $\mathsf {BC}$
-learnability and non-uniform learnability coincide. In order to obtain a learner for
$\mathsf {BC}$
-learnability and non-uniform learnability coincide. In order to obtain a learner for
 $\vec x$
from a
$\vec x$
from a
 $\mathsf {BC}$
-learner, we just have to fix some more information.
$\mathsf {BC}$
-learner, we just have to fix some more information.
Theorem 2. An equivalence relation
 $\mathrel {E}$
is non-uniformly learnable if and only if it is non-uniformly
$\mathrel {E}$
is non-uniformly learnable if and only if it is non-uniformly
 $\mathsf {BC}$
-learnable.
$\mathsf {BC}$
-learnable.
Proof. Clearly, any non-uniformly learnable equivalence relation is non-uniformly
 $\mathsf {BC}$
-learnable. On the other hand, say that
$\mathsf {BC}$
-learnable. On the other hand, say that
 $(l_n)_{n\in \omega }$
gives a
$(l_n)_{n\in \omega }$
gives a
 $\mathsf {BC}$
learner for the sequence
$\mathsf {BC}$
learner for the sequence
 $\vec x$
and associate with every i, the set
$\vec x$
and associate with every i, the set
 $e_i=\{ j: x_j\mathrel {E} x_i\}$
. Now, define a function L by
$e_i=\{ j: x_j\mathrel {E} x_i\}$
. Now, define a function L by
 $L(x,\vec x,n)=\min j [ j\in e_{l_{n}(x,\vec x)}]$
. We claim that L is a learner for E on
$L(x,\vec x,n)=\min j [ j\in e_{l_{n}(x,\vec x)}]$
. We claim that L is a learner for E on
 $\vec x$
. Clearly, L is continuous on every n. Say that
$\vec x$
. Clearly, L is continuous on every n. Say that
 $x\mathrel {E} x_i$
, then for almost every n,
$x\mathrel {E} x_i$
, then for almost every n,
 $l_n(\vec x,x)\in e_i$
. So, for almost every n,
$l_n(\vec x,x)\in e_i$
. So, for almost every n,
 $L(x,\vec x,n)=\min j [j \in e_i]$
and thus L learns
$L(x,\vec x,n)=\min j [j \in e_i]$
and thus L learns
 $\mathrel {E}$
on
$\mathrel {E}$
on
 $\vec x$
.
$\vec x$
.
Recall that an equivalence relation is countable if all its equivalence classes are countable. Countable Borel equivalence relations play an important role in descriptive set theory and have seen much attention in the past decades, see [Reference Kechris12] for a summary of these developments. Unfortunately, non-uniform learnability does not provide information when it comes to countable equivalence relations.
Proposition 3. Every countable equivalence relation on a Polish space is non-uniformly learnable by learners not giving false positives.
Proof. Let
 $\mathrel {E}$
be a countable equivalence relation. Given
$\mathrel {E}$
be a countable equivalence relation. Given
 $\vec {x}$
, let
$\vec {x}$
, let
 $y_{i,j}$
be the j-th element in the enumeration of the equivalence class for
$y_{i,j}$
be the j-th element in the enumeration of the equivalence class for
 $x_i$
and for every n, define the continuous function
$x_i$
and for every n, define the continuous function
 $$\begin{align*}l_n(x,\vec{x})= \begin{cases} (\min i<n) [ (\exists j<n)\ y_{i,j}\operatorname{\mathrm{\upharpoonright}} n=x\operatorname{\mathrm{\upharpoonright}} n] & \text{if such }i\text{ exists}\\ n& \text{otherwise}\end{cases}. \end{align*}$$
$$\begin{align*}l_n(x,\vec{x})= \begin{cases} (\min i<n) [ (\exists j<n)\ y_{i,j}\operatorname{\mathrm{\upharpoonright}} n=x\operatorname{\mathrm{\upharpoonright}} n] & \text{if such }i\text{ exists}\\ n& \text{otherwise}\end{cases}. \end{align*}$$
It is not hard to see that the so-defined sequence of functions defines a learner giving no false positives.
2.2 Uniform learnability
Definition 3. Let
 $\mathrel {E}$
be an equivalence relation on a Polish space X and assume
$\mathrel {E}$
be an equivalence relation on a Polish space X and assume
 $\omega $
is equipped with the discrete topology. We say that
$\omega $
is equipped with the discrete topology. We say that
 $\mathrel {E}$
is uniformly learnable, or just learnable, if there are continuous functions
$\mathrel {E}$
is uniformly learnable, or just learnable, if there are continuous functions
 $l_n: X^\omega \times X\to \omega $
such that for every
$l_n: X^\omega \times X\to \omega $
such that for every
 $x\in X$
and
$x\in X$
and
 $\vec x=(x_i)_{i\in \omega }\in X^\omega $
, if
$\vec x=(x_i)_{i\in \omega }\in X^\omega $
, if
 $x\mathrel {E} x_i$
for some
$x\mathrel {E} x_i$
for some
 $i\in \omega $
, then
$i\in \omega $
, then
 $L(x,\vec x)=\lim l_n(\vec x, x)$
exists and
$L(x,\vec x)=\lim l_n(\vec x, x)$
exists and
 $x \mathrel {E} x_{L(x,\vec x)}$
. We call the partial function L a learner for E and write
$x \mathrel {E} x_{L(x,\vec x)}$
. We call the partial function L a learner for E and write
 $L(x,\vec x,n)$
for
$L(x,\vec x,n)$
for
 $l_n(\vec x, x)$
.
$l_n(\vec x, x)$
.
Definition 4. A learner
 $L=\lim l_n$
is a-computable for
$L=\lim l_n$
is a-computable for
 $a\in 2^\omega $
if there is an a-recursive function
$a\in 2^\omega $
if there is an a-recursive function
 $f:\omega \to \omega $
such that
$f:\omega \to \omega $
such that
 $\Phi _{f(n)}^a=l_n$
where
$\Phi _{f(n)}^a=l_n$
where
 $(\Phi _i)_{i\in \omega }$
is a standard enumeration of Turing operators.
$(\Phi _i)_{i\in \omega }$
is a standard enumeration of Turing operators.
Clearly, every learner is a-computable for some
 $a\in 2^\omega $
. The main result of this section is a characterization of the uniformly learnable equivalence relations in terms of their Borel complexity. Our proof will rely on an analysis of the Cohen forcing relation. For a concise overview of forcing both in the computability theory and set theory setting we suggest [Reference Chong and Yu4]. Let us quickly summarize the main points. The forcing partial orders we will use are
$a\in 2^\omega $
. The main result of this section is a characterization of the uniformly learnable equivalence relations in terms of their Borel complexity. Our proof will rely on an analysis of the Cohen forcing relation. For a concise overview of forcing both in the computability theory and set theory setting we suggest [Reference Chong and Yu4]. Let us quickly summarize the main points. The forcing partial orders we will use are
 $\mathbb P$
given by the set of finite binary strings ordered by extension and its products
$\mathbb P$
given by the set of finite binary strings ordered by extension and its products
 $\mathbb P^n$
and
$\mathbb P^n$
and
 $\mathbb P^{<\omega }=\bigcup _{n\in \omega } \mathbb P^n$
. The ordering on the latter sets is defined as the lexicographic ordering induced by the ordering on
$\mathbb P^{<\omega }=\bigcup _{n\in \omega } \mathbb P^n$
. The ordering on the latter sets is defined as the lexicographic ordering induced by the ordering on
 $\mathbb P$
. Given
$\mathbb P$
. Given
 $p\in \mathbb P$
we let
$p\in \mathbb P$
we let ![]() denote the basic open set of all infinite extensions of p, and likewise for
denote the basic open set of all infinite extensions of p, and likewise for
 $\mathbb P^{<\omega }$
and
$\mathbb P^{<\omega }$
and
 $\mathbb P^{n}$
. The definition of our forcing relation is standard, where
$\mathbb P^{n}$
. The definition of our forcing relation is standard, where
 $p\Vdash {\varphi }(\dot g)$
if for every generic
$p\Vdash {\varphi }(\dot g)$
if for every generic ![]() ,
,
 ${\varphi }(x)$
. The syntactic definition of our forcing relations are standard and can be found in any textbook on the topic. The only thing of note is that we use the strong forcing relation, i.e., for a property of the type
${\varphi }(x)$
. The syntactic definition of our forcing relations are standard and can be found in any textbook on the topic. The only thing of note is that we use the strong forcing relation, i.e., for a property of the type
 $\exists n{\varphi }(\dot g,n)$
we have that
$\exists n{\varphi }(\dot g,n)$
we have that
 $p\Vdash \exists n {\varphi }(\dot g,n)$
if and only if
$p\Vdash \exists n {\varphi }(\dot g,n)$
if and only if
 $\exists n_0\leq |p|$
such that
$\exists n_0\leq |p|$
such that
 $p\Vdash {\varphi }(\dot g,n_0)$
. Furthermore, recall that an element y is n-generic relative to x if it decides every
$p\Vdash {\varphi }(\dot g,n_0)$
. Furthermore, recall that an element y is n-generic relative to x if it decides every
 $\Sigma ^0_n$
statement about x and that a property holds for sufficiently generic elements y relative to x, if it holds for all n-generics relative to x for some
$\Sigma ^0_n$
statement about x and that a property holds for sufficiently generic elements y relative to x, if it holds for all n-generics relative to x for some
 $n\in \omega $
.
$n\in \omega $
.
Proposition 4. Let
 $\mathrel {E}$
be an equivalence relation learnable by an a-computable learner. If for every
$\mathrel {E}$
be an equivalence relation learnable by an a-computable learner. If for every
 $x\in 2^\omega $
there exists
$x\in 2^\omega $
there exists
 $z\in 2^\omega $
, 1-generic relative to
$z\in 2^\omega $
, 1-generic relative to
 $x\oplus a$
, such that
$x\oplus a$
, such that
 $x\mathrel {E} z$
, then there exists
$x\mathrel {E} z$
, then there exists
 $p\in 2^{<\omega }$
such that for all
$p\in 2^{<\omega }$
such that for all ![]() we have
we have
 $x\mathrel {E} y$
.
$x\mathrel {E} y$
.
Proof. Suppose that
 $\mathrel {E}$
is learnable by an a-computable learner L. Fix a real x and
$\mathrel {E}$
is learnable by an a-computable learner L. Fix a real x and
 $\vec g$
, a sequence of mutually 1-generics relative to
$\vec g$
, a sequence of mutually 1-generics relative to
 $x\bigoplus a$
. By learnability, if there is
$x\bigoplus a$
. By learnability, if there is
 $g\in \vec g$
such that
$g\in \vec g$
such that
 $x\mathrel {E} g$
, then
$x\mathrel {E} g$
, then
 $L(x,\vec g)$
converges. Suppose that there exists k and
$L(x,\vec g)$
converges. Suppose that there exists k and
 $n_0$
such that for all
$n_0$
such that for all
 $m>n_0$
we have
$m>n_0$
we have
 $L(x,\vec g, m)=k$
and fix such k and
$L(x,\vec g, m)=k$
and fix such k and
 $n_0$
. We will argue that then there exists a finite
$n_0$
. We will argue that then there exists a finite
 $\vec p$
with
$\vec p$
with
 $p_i\in 2^{<\omega }$
that already forces the convergence. Consider a set C consisting of finite
$p_i\in 2^{<\omega }$
that already forces the convergence. Consider a set C consisting of finite
 $\vec h$
with
$\vec h$
with
 $h_i\in 2^{<\omega }$
such that for some
$h_i\in 2^{<\omega }$
such that for some
 $n>n_0$
the learner diverges from k, i.e.,
$n>n_0$
the learner diverges from k, i.e.,
 $L(x,\vec h,n)\neq k$
. This set is recursively enumerable in x and a and
$L(x,\vec h,n)\neq k$
. This set is recursively enumerable in x and a and
 $\vec g$
has to either meet or avoid it. If no finite
$\vec g$
has to either meet or avoid it. If no finite
 $\vec p$
forces the convergence, then every initial segment of
$\vec p$
forces the convergence, then every initial segment of
 $\vec g$
can be extended to an element of C. But then
$\vec g$
can be extended to an element of C. But then
 $\vec g$
cannot avoid C, contradicting the definition of
$\vec g$
cannot avoid C, contradicting the definition of
 $n_0$
.
$n_0$
.
So take
 $\vec p$
such that
$\vec p$
such that
 $\vec p\Vdash (\forall m>n_0) L(x,\dot {\vec g},m)=k$
and assume without loss of generality that
$\vec p\Vdash (\forall m>n_0) L(x,\dot {\vec g},m)=k$
and assume without loss of generality that
 $k<|\vec p|$
. Then for any
$k<|\vec p|$
. Then for any ![]() ,
,
 $L(x,p_1,\dots , y, \dots , p_{|\vec p|})=k$
, since by the use principle for continuous functions if there exists
$L(x,p_1,\dots , y, \dots , p_{|\vec p|})=k$
, since by the use principle for continuous functions if there exists
 $q\succeq p_k$
such that
$q\succeq p_k$
such that
 $L(x,p_1,\dots , q,\dots , p_{|\vec p|},m)=k$
for any m, then
$L(x,p_1,\dots , q,\dots , p_{|\vec p|},m)=k$
for any m, then
 $L(x,p_1,\dots r,\dots , p_{|\vec p|},m)=k$
for all
$L(x,p_1,\dots r,\dots , p_{|\vec p|},m)=k$
for all
 $r\succeq q$
.
$r\succeq q$
.
Corollary 5. If
 $\mathrel {E}$
is an equivalence relation learnable by an a-computable learner and the
$\mathrel {E}$
is an equivalence relation learnable by an a-computable learner and the
 $\mathrel {E}$
-equivalence class of x is countable, then x is not
$\mathrel {E}$
-equivalence class of x is countable, then x is not
 $\mathrel {E}$
-equivalent to any y which is 1-generic relative to
$\mathrel {E}$
-equivalent to any y which is 1-generic relative to
 $x\oplus a$
.
$x\oplus a$
.
Theorem 6. Let
 $\mathrel {E}$
be an equivalence relation. Then
$\mathrel {E}$
be an equivalence relation. Then
 $\mathrel {E}$
is learnable by an a-computable learner if and only if
$\mathrel {E}$
is learnable by an a-computable learner if and only if
 $\mathrel {E}$
is
$\mathrel {E}$
is
 $\Sigma ^0_2(a)$
.
$\Sigma ^0_2(a)$
.
Proof. (
 $\Rightarrow $
) Suppose that
$\Rightarrow $
) Suppose that
 $\mathrel {E}$
is learnable by an a-computable learner L. Take arbitrary x and y such that
$\mathrel {E}$
is learnable by an a-computable learner L. Take arbitrary x and y such that
 $x\mathrel {E} y$
and let
$x\mathrel {E} y$
and let
 $\vec g$
be a countable sequence of reals mutually sufficiently generic relative to
$\vec g$
be a countable sequence of reals mutually sufficiently generic relative to
 $x\oplus y\oplus a$
. We analyze the behavior of
$x\oplus y\oplus a$
. We analyze the behavior of
 $L(x,y^\smallfrown \vec g)$
and
$L(x,y^\smallfrown \vec g)$
and
 $L(y,x^\smallfrown \vec g)$
. Since
$L(y,x^\smallfrown \vec g)$
. Since
 $x\mathrel {E} y$
, in both cases, the learner has to converge to either
$x\mathrel {E} y$
, in both cases, the learner has to converge to either
 $0$
or, if
$0$
or, if
 $\vec g$
contains a
$\vec g$
contains a
 $g_i$
such that
$g_i$
such that
 $g_i\mathrel {E} x$
, some other index. Hence, we have two possibilities to consider.
$g_i\mathrel {E} x$
, some other index. Hence, we have two possibilities to consider.
Case 1:
 $L(x,y^\smallfrown \vec g)$
or
$L(x,y^\smallfrown \vec g)$
or
 $L(y,x^\smallfrown \vec g)$
converges to
$L(y,x^\smallfrown \vec g)$
converges to
 $0$
. Suppose without loss of generality that the latter is the case. Fix
$0$
. Suppose without loss of generality that the latter is the case. Fix
 $n_0$
such that for all
$n_0$
such that for all
 $m>n_0$
the value of
$m>n_0$
the value of
 $L(y,x^\smallfrown \vec g,m)$
doesn’t change. Then, by the mutual genericity of
$L(y,x^\smallfrown \vec g,m)$
doesn’t change. Then, by the mutual genericity of
 $\vec g$
relative to
$\vec g$
relative to
 $x\oplus y\oplus a$
there exists a finite
$x\oplus y\oplus a$
there exists a finite
 $\vec p\in {2^{<\omega }}^{<\omega }$
such that
$\vec p\in {2^{<\omega }}^{<\omega }$
such that
 $$\begin{align*}\vec p\Vdash (\forall m>n_0) (L(y,x^\smallfrown \dot{\vec g},m)\downarrow\implies L(y,x^\smallfrown \dot{\vec g},m)=0). \end{align*}$$
$$\begin{align*}\vec p\Vdash (\forall m>n_0) (L(y,x^\smallfrown \dot{\vec g},m)\downarrow\implies L(y,x^\smallfrown \dot{\vec g},m)=0). \end{align*}$$
By the definability of forcing we get that x and y satisfy
 $$ \begin{align} \exists \vec p, n_0 (\forall \vec q \leq \vec p)(\forall m>n_0) (L(y,x^\smallfrown\vec q,m)\downarrow\implies L(y,x^\smallfrown\vec q,m)=0). \end{align} $$
$$ \begin{align} \exists \vec p, n_0 (\forall \vec q \leq \vec p)(\forall m>n_0) (L(y,x^\smallfrown\vec q,m)\downarrow\implies L(y,x^\smallfrown\vec q,m)=0). \end{align} $$
By the same reasoning, if
 $L(x,y^\smallfrown \vec g)$
converges to
$L(x,y^\smallfrown \vec g)$
converges to
 $0$
, then the following is satisfied by x and y
$0$
, then the following is satisfied by x and y
 $$ \begin{align} \exists \vec p, n_0 (\forall \vec q \leq \vec p)(\forall m>n_0) (L(x,y^\smallfrown\vec q,m)\downarrow\implies L(x,y^\smallfrown\vec q,m)=0). \end{align} $$
$$ \begin{align} \exists \vec p, n_0 (\forall \vec q \leq \vec p)(\forall m>n_0) (L(x,y^\smallfrown\vec q,m)\downarrow\implies L(x,y^\smallfrown\vec q,m)=0). \end{align} $$
Case 2:
 $L(x,y^\smallfrown \vec g)=j_1$
and
$L(x,y^\smallfrown \vec g)=j_1$
and
 $L(y,x^\smallfrown \vec g)=j_2$
for some indices
$L(y,x^\smallfrown \vec g)=j_2$
for some indices
 $j_1,j_2\neq 0$
. Again, by similar genericity arguments as in Case 1, this is forced by some finite
$j_1,j_2\neq 0$
. Again, by similar genericity arguments as in Case 1, this is forced by some finite
 $\vec p_1=p_{1,0},p_{1,1},\ldots $
, respectively,
$\vec p_1=p_{1,0},p_{1,1},\ldots $
, respectively,
 $\vec p_2=p_{2,0},p_{2,1},\ldots $
. Note that then for any
$\vec p_2=p_{2,0},p_{2,1},\ldots $
. Note that then for any
 $h_1\succ p_{1,j_1}$
,
$h_1\succ p_{1,j_1}$
,
 $h_2\succ p_{2,j_2}$
,
$h_2\succ p_{2,j_2}$
,
 $$\begin{align*}L(x,y^\smallfrown (g_0,\dots, g_{j_1-1},h_1, g_{j_1+1},\dots))=j_1\end{align*}$$
$$\begin{align*}L(x,y^\smallfrown (g_0,\dots, g_{j_1-1},h_1, g_{j_1+1},\dots))=j_1\end{align*}$$
and
 $$\begin{align*}L(y,x^\smallfrown (g_0,\dots, g_{j_2-1},h_2 ,g_{j_2+1},\dots))=j_2.\end{align*}$$
$$\begin{align*}L(y,x^\smallfrown (g_0,\dots, g_{j_2-1},h_2 ,g_{j_2+1},\dots))=j_2.\end{align*}$$
Now, fix
 $h\succ p_{1,j_1}$
and
$h\succ p_{1,j_1}$
and
 $\vec h\succ p_{2,j_2}$
(i.e., every element of
$\vec h\succ p_{2,j_2}$
(i.e., every element of
 $\vec h$
extends
$\vec h$
extends
 $p_{2,j_2}$
) mutually sufficiently generic relative to a and look at
$p_{2,j_2}$
) mutually sufficiently generic relative to a and look at
 $L(h, \vec h)$
. By transitivity of
$L(h, \vec h)$
. By transitivity of
 $\mathrel {E}$
it will stabilize to some k, and as
$\mathrel {E}$
it will stabilize to some k, and as
 $h,\vec h$
are mutually generic, this is forced. Hence, x and y satisfy
$h,\vec h$
are mutually generic, this is forced. Hence, x and y satisfy
 $$ \begin{align} \exists n_0 \exists \vec p_1, \vec p_2 \exists j_1,j_2 (\forall n>n_0) (\forall \vec q\leq \vec p_1) \left(L(x,y^\smallfrown \vec q,n)\downarrow\right. &\left.\implies L(x,y^\smallfrown \vec q,n)=j_1\right)\nonumber\\ \land (\forall \vec q\leq \vec p_2) \left(L(y,x^\smallfrown \vec q,n)\downarrow\right. &\left.\implies L(y,x^\smallfrown \vec q,n)=j_2\right)\nonumber\\ \land \exists k (\exists r\leq p_{1,j_1}) (\exists\vec r \leq p_{2,j_2}) (\forall n>n_0)\qquad\quad&\nonumber\\ (\forall q\leq r)(\forall \vec q\leq \vec r) \left( L(q,\vec q,n)\downarrow\right. &\left.\implies L(q,\vec q,n)=k\right). \end{align} $$
$$ \begin{align} \exists n_0 \exists \vec p_1, \vec p_2 \exists j_1,j_2 (\forall n>n_0) (\forall \vec q\leq \vec p_1) \left(L(x,y^\smallfrown \vec q,n)\downarrow\right. &\left.\implies L(x,y^\smallfrown \vec q,n)=j_1\right)\nonumber\\ \land (\forall \vec q\leq \vec p_2) \left(L(y,x^\smallfrown \vec q,n)\downarrow\right. &\left.\implies L(y,x^\smallfrown \vec q,n)=j_2\right)\nonumber\\ \land \exists k (\exists r\leq p_{1,j_1}) (\exists\vec r \leq p_{2,j_2}) (\forall n>n_0)\qquad\quad&\nonumber\\ (\forall q\leq r)(\forall \vec q\leq \vec r) \left( L(q,\vec q,n)\downarrow\right. &\left.\implies L(q,\vec q,n)=k\right). \end{align} $$
We claim that the disjunction of Eq. (*), Eq. (†), and Eq. (‡) defines
 $\mathrel {E}$
. As argued above, if
$\mathrel {E}$
. As argued above, if
 $x\mathrel {E} y$
, then one of the disjuncts is satisfied. On the other hand, if
$x\mathrel {E} y$
, then one of the disjuncts is satisfied. On the other hand, if
 $x\not\!\! {\mathrel {E}} y$
, then the only way Eq. (*), Eq. (†), and Eq. (‡) can be satisfied is if L produces false positives. The following claim disposes of this possibility in case the learner gives false positives in the third conjunct of Eq. (‡). The other cases follow by a similar proof.
$x\not\!\! {\mathrel {E}} y$
, then the only way Eq. (*), Eq. (†), and Eq. (‡) can be satisfied is if L produces false positives. The following claim disposes of this possibility in case the learner gives false positives in the third conjunct of Eq. (‡). The other cases follow by a similar proof.
Claim 6.1. If
 $g,\vec g$
is a sequence of mutually sufficiently generics relative to a and
$g,\vec g$
is a sequence of mutually sufficiently generics relative to a and
 $L(g,\vec g)=k$
is forced by
$L(g,\vec g)=k$
is forced by
 $p,\vec p$
, then
$p,\vec p$
, then
 $L(g,\vec g)$
does not produce false positives for any
$L(g,\vec g)$
does not produce false positives for any
 $h,\vec h\succ p,\vec p$
.
$h,\vec h\succ p,\vec p$
.
Proof. Towards a contradiction assume that
 $L(h,\vec h)=k$
is a false positive where without loss of generality
$L(h,\vec h)=k$
is a false positive where without loss of generality
 $k<|\vec p|$
. By definition, this is only possible if
$k<|\vec p|$
. By definition, this is only possible if
 $h\not\!\! {\mathrel {E}} h_i$
for all
$h\not\!\! {\mathrel {E}} h_i$
for all
 $i\in \omega $
. As
$i\in \omega $
. As
 $L(h,\vec h)=k$
is forced by
$L(h,\vec h)=k$
is forced by
 $p,\vec p$
we have that
$p,\vec p$
we have that
 $L(h,(h_0,\dots h_{|\vec p|},h,h_{|\vec p|+1},\dots ))=k$
. But, by reflexivity,
$L(h,(h_0,\dots h_{|\vec p|},h,h_{|\vec p|+1},\dots ))=k$
. But, by reflexivity,
 $h\mathrel {E} h$
and thus
$h\mathrel {E} h$
and thus
 $h\mathrel {E} h_k$
, contradicting our assumption.
$h\mathrel {E} h_k$
, contradicting our assumption.
(
 $\Leftarrow $
) Suppose that there is an
$\Leftarrow $
) Suppose that there is an
 $X\in 2^{\omega }$
and an X-computable formula
$X\in 2^{\omega }$
and an X-computable formula
 ${\varphi }$
such that for all
${\varphi }$
such that for all
 $x,y$
we have
$x,y$
we have
 $x\mathrel {E} y$
if and only if
$x\mathrel {E} y$
if and only if
 $\exists n \forall m\ {\varphi }(x,y,n,m)$
. The construction of an X-computable learner for
$\exists n \forall m\ {\varphi }(x,y,n,m)$
. The construction of an X-computable learner for
 $\mathrel {E}$
given input
$\mathrel {E}$
given input
 $x,\vec y$
is now straightforward. The learner works with an enumeration
$x,\vec y$
is now straightforward. The learner works with an enumeration
 $(a_1,b_1),(a_2,b_2)\ldots $
of all pairs of natural numbers. Given
$(a_1,b_1),(a_2,b_2)\ldots $
of all pairs of natural numbers. Given
 $(a_i,b_i)$
, the learner outputs
$(a_i,b_i)$
, the learner outputs
 $a_i$
until it finds a witness for a failure of the universal formula, i.e., until it finds m such that
$a_i$
until it finds a witness for a failure of the universal formula, i.e., until it finds m such that
 $\neg {\varphi }(x,\vec y(a_i),b_i,m)$
. If this happens, the learner proceeds to the next pair. Now, if
$\neg {\varphi }(x,\vec y(a_i),b_i,m)$
. If this happens, the learner proceeds to the next pair. Now, if
 $x\mathrel {E} y$
, then for some
$x\mathrel {E} y$
, then for some
 $a_i$
and
$a_i$
and
 $b_i$
we have
$b_i$
we have
 $\forall m\ {\varphi }(x,\vec y(a_i),b_i,m)$
and the learner converges on
$\forall m\ {\varphi }(x,\vec y(a_i),b_i,m)$
and the learner converges on
 $a_i$
.
$a_i$
.
Recall that an equivalence relation
 $E\subseteq X^2$
is reducible to an equivalence relation
$E\subseteq X^2$
is reducible to an equivalence relation
 $F\subseteq Y^2$
, if there is a function
$F\subseteq Y^2$
, if there is a function
 $f: X\to Y$
such that for all
$f: X\to Y$
such that for all
 $x_1,x_2\in X$
,
$x_1,x_2\in X$
,
 $x_1\mathrel {E} x_2$
if and only if
$x_1\mathrel {E} x_2$
if and only if
 $f(x_1)\mathrel {F} f(x_2)$
. The relation
$f(x_1)\mathrel {F} f(x_2)$
. The relation
 $\mathrel {E}$
is Borel (continuously) reducible to
$\mathrel {E}$
is Borel (continuously) reducible to
 $\mathrel {F}$
if f is Borel (continuous).
$\mathrel {F}$
if f is Borel (continuous).
Theorem 6 is in stark contrast to the result by Bazhenov, Cipriani, and San Mauro [Reference Bazhenov, Cipriani and Mauro2] that a countable class of structures is explanatory learnable if and only if it is continuously reducible to
 $E_0$
, the eventual equality relation on
$E_0$
, the eventual equality relation on
 $2^\omega $
. While
$2^\omega $
. While
 $E_0$
is
$E_0$
is
 $\boldsymbol {\Sigma }^0_2$
by its standard definition
$\boldsymbol {\Sigma }^0_2$
by its standard definition
 $$\begin{align*}x\mathrel{E}_0 y \iff \exists n(\forall m>n) x(m)=y(m),\end{align*}$$
$$\begin{align*}x\mathrel{E}_0 y \iff \exists n(\forall m>n) x(m)=y(m),\end{align*}$$
there are many
 $\boldsymbol {\Sigma }^0_2$
equivalence relations that are not Borel reducible to
$\boldsymbol {\Sigma }^0_2$
equivalence relations that are not Borel reducible to
 $\mathrel {E}_0$
. An important example is the equivalence relation
$\mathrel {E}_0$
. An important example is the equivalence relation
 $E_\infty $
, the shift action of
$E_\infty $
, the shift action of
 $F_2$
—the free group on
$F_2$
—the free group on
 $2$
generators—on
$2$
generators—on
 $2^{F_2}$
, which is a Borel-complete countable equivalence relation and thus vastly more complicated than
$2^{F_2}$
, which is a Borel-complete countable equivalence relation and thus vastly more complicated than
 $\mathrel {E}_0$
from the point of view of Borel reducibility [Reference Dougherty, Jackson and Kechris5].
$\mathrel {E}_0$
from the point of view of Borel reducibility [Reference Dougherty, Jackson and Kechris5].
Notice that the definition of the learner from a
 $\boldsymbol {\Sigma }^0_2$
description of
$\boldsymbol {\Sigma }^0_2$
description of
 $\mathrel {E}$
in the proof of Theorem 6 produces a learner that does not give false positives, and that we can get
$\mathrel {E}$
in the proof of Theorem 6 produces a learner that does not give false positives, and that we can get
 $\boldsymbol {\Sigma }^0_2$
definitions of learnable equivalence relations regardless if their learners produce false positives or not. Thus, we obtain the following.
$\boldsymbol {\Sigma }^0_2$
definitions of learnable equivalence relations regardless if their learners produce false positives or not. Thus, we obtain the following.
Corollary 7. An equivalence relation E is learnable if and only if it is learnable without false positives.
Let
 $\Gamma $
be a class of equivalence relations and say that an equivalence relation
$\Gamma $
be a class of equivalence relations and say that an equivalence relation
 $E\in \Gamma $
is Borel (continuous)
$E\in \Gamma $
is Borel (continuous)
 $\Gamma $
-complete if every
$\Gamma $
-complete if every
 $F\in \Gamma $
Borel (continuously) reduces to E. One of the most tantalizing questions about a class of equivalence relations
$F\in \Gamma $
Borel (continuously) reduces to E. One of the most tantalizing questions about a class of equivalence relations
 $\Gamma $
is whether there is a Borel (continuous)
$\Gamma $
is whether there is a Borel (continuous)
 $\Gamma $
-complete object. We thus ask the following.
$\Gamma $
-complete object. We thus ask the following.
Question 1. Does there exist a Borel (continuous) learnable complete equivalence relation?
By Theorem 6 one could equivalently ask whether there is a
 $\boldsymbol {\Sigma }^0_2$
-complete equivalence relation. It turns out that this is a difficult and long-standing open problem in descriptive set theory [Reference Lecomte13].
$\boldsymbol {\Sigma }^0_2$
-complete equivalence relation. It turns out that this is a difficult and long-standing open problem in descriptive set theory [Reference Lecomte13].
On the other hand, given a Polish space X, recall that
 $A\subseteq X$
is
$A\subseteq X$
is
 $K_\sigma $
if A is a union of compact subsets of X. Rosendal [Reference Rosendal18] showed that there exists a Borel complete
$K_\sigma $
if A is a union of compact subsets of X. Rosendal [Reference Rosendal18] showed that there exists a Borel complete
 $K_\sigma $
equivalence relation. One example of a complete
$K_\sigma $
equivalence relation. One example of a complete
 $K_\sigma $
equivalence relation is the oscillation relation O [Reference Rosendal18] which can be defined on
$K_\sigma $
equivalence relation is the oscillation relation O [Reference Rosendal18] which can be defined on
 $2^\omega $
by
$2^\omega $
by
 $$\begin{align*}\begin{aligned} x\mathrel{O} y \iff&\\ \exists N \forall n,m &\left((\forall j\in (n,n+m)) x(j)=0 \implies |\{ j\in (n,n+m): y(j)=1\}|<N\right)\\ \land &\left((\forall j\in (n,n+m)) y(j)=0 \implies |\{ j\in (n,n+m): x(j)=1\}|<N \right)\end{aligned}.\end{align*}$$
$$\begin{align*}\begin{aligned} x\mathrel{O} y \iff&\\ \exists N \forall n,m &\left((\forall j\in (n,n+m)) x(j)=0 \implies |\{ j\in (n,n+m): y(j)=1\}|<N\right)\\ \land &\left((\forall j\in (n,n+m)) y(j)=0 \implies |\{ j\in (n,n+m): x(j)=1\}|<N \right)\end{aligned}.\end{align*}$$
Remark. The oscillation equivalence relation is usually defined on the space of infinite increasing sequences of natural numbers
 $[\omega ]^\omega $
. Our definition of O above is not equivalent, as we have one additional equivalence class consisting of all finite strings. However, the function mapping
$[\omega ]^\omega $
. Our definition of O above is not equivalent, as we have one additional equivalence class consisting of all finite strings. However, the function mapping
 $(a_0,\dots )$
to the characteristic function of the associated set
$(a_0,\dots )$
to the characteristic function of the associated set
 $\{ a_i: i\in \omega \}$
is a continuous embedding of the oscillation equivalence relation on
$\{ a_i: i\in \omega \}$
is a continuous embedding of the oscillation equivalence relation on
 $[\omega ]^\omega $
into O.
$[\omega ]^\omega $
into O.
Since every
 $\boldsymbol {\Sigma }^0_2$
relation on a compact space is
$\boldsymbol {\Sigma }^0_2$
relation on a compact space is
 $K_\sigma $
we get the following.
$K_\sigma $
we get the following.
Proposition 8. The oscillation equivalence relation O is Borel complete among learnable equivalence relations on
 $2^\omega $
.
$2^\omega $
.
2.3 Uniform
$\mathsf {BC}$
-learnability

Definition 5. Let E be an equivalence relation on a Polish space X and assume
 $\omega $
is equipped with the discrete topology. We say that E is (uniformly)
$\omega $
is equipped with the discrete topology. We say that E is (uniformly)
 $\mathsf {BC}$
-learnable, or just BC-learnable, if there are continuous functions
$\mathsf {BC}$
-learnable, or just BC-learnable, if there are continuous functions
 $l_n: X^\omega \times X\to \omega $
such that for every
$l_n: X^\omega \times X\to \omega $
such that for every
 $x\in X$
and
$x\in X$
and
 $\vec x=(x_i)_{i\in \omega }\in X^\omega $
, if
$\vec x=(x_i)_{i\in \omega }\in X^\omega $
, if
 $xEx_i$
for some
$xEx_i$
for some
 $i\in \omega $
, then for almost all n,
$i\in \omega $
, then for almost all n,
 $xEx_{l_n(\vec x, x)}$
. We call the function
$xEx_{l_n(\vec x, x)}$
. We call the function
 $L(x,\vec x, n)=l_n(\vec x, x)$
a
$L(x,\vec x, n)=l_n(\vec x, x)$
a
 $\mathsf {BC}$
-learner for
$\mathsf {BC}$
-learner for
 $\mathrel {E}$
.
$\mathrel {E}$
.
The rest of this section is devoted to showing that the
 $\mathsf {BC}$
learnable and learnable equivalence relations coincide. This will follow from a series of lemmas.
$\mathsf {BC}$
learnable and learnable equivalence relations coincide. This will follow from a series of lemmas.
Lemma 9. If
 $\mathrel {E}$
is
$\mathrel {E}$
is
 $\mathsf {BC}$
-learnable, then every equivalence class is
$\mathsf {BC}$
-learnable, then every equivalence class is
 $\boldsymbol {\Sigma }^0_2$
.
$\boldsymbol {\Sigma }^0_2$
.
Proof. Suppose that
 $\mathrel {E}$
is
$\mathrel {E}$
is
 $\mathsf {BC}$
-learnable and that
$\mathsf {BC}$
-learnable and that
 $[x]_E$
is not open. Pick
$[x]_E$
is not open. Pick
 $y\in [x]_E\setminus int([x]_E)$
, where
$y\in [x]_E\setminus int([x]_E)$
, where
 $int([x]_E)$
denotes the interior of
$int([x]_E)$
denotes the interior of
 $[x]_E$
. Then for every n, there is
$[x]_E$
. Then for every n, there is ![]() . Fix such a sequence
. Fix such a sequence
 $(b_n)_{n\in \omega }$
. Now, given a
$(b_n)_{n\in \omega }$
. Now, given a
 $\mathsf {BC}$
-learner L and
$\mathsf {BC}$
-learner L and
 $z\in 2^\omega $
run the following procedure defined in stages.
$z\in 2^\omega $
run the following procedure defined in stages.
At each stage s we will run
 $L(y,(z,a^{s-1}_1,a^{s-1}_2,\dots ),s)$
. Here, the
$L(y,(z,a^{s-1}_1,a^{s-1}_2,\dots ),s)$
. Here, the
 $a^s_j$
are either prefixes of y or they are equal to some element
$a^s_j$
are either prefixes of y or they are equal to some element
 $b_n\in 2^\omega $
from the sequence defined above. To start, let
$b_n\in 2^\omega $
from the sequence defined above. To start, let
 $a^{-1}_j=\emptyset $
for all j and
$a^{-1}_j=\emptyset $
for all j and
 $i_{-1}=0$
.
$i_{-1}=0$
.
Assume we have defined
 $a^{s-1}_j$
for all j and
$a^{s-1}_j$
for all j and
 $i_{s-1}=L(y,(z,a^{s-1}_1,a^{s-1}_2,\dots ),s-1)$
, and suppose that k is largest such that for all
$i_{s-1}=L(y,(z,a^{s-1}_1,a^{s-1}_2,\dots ),s-1)$
, and suppose that k is largest such that for all
 $j<k$
,
$j<k$
,
 $a^{s-1}_j$
is equal to some
$a^{s-1}_j$
is equal to some
 $b_n$
. For all
$b_n$
. For all
 $j<k$
, set
$j<k$
, set
 $a^{s}_j=a^{s-1}_j$
. Then let
$a^{s}_j=a^{s-1}_j$
. Then let
 $(c_{k},\dots )$
be the lexicographical minimal sequence such that
$(c_{k},\dots )$
be the lexicographical minimal sequence such that
 $a^{s-1}_j\preceq c_j\prec y$
for all
$a^{s-1}_j\preceq c_j\prec y$
for all
 $j\geq k$
and for some
$j\geq k$
and for some
 $i_s$
,
$i_s$
,
 $$\begin{align*}L(y,(z,a^{s}_0,\dots, a^{s}_{k-1},c_{k},\dots),s)\downarrow=i_s.\end{align*}$$
$$\begin{align*}L(y,(z,a^{s}_0,\dots, a^{s}_{k-1},c_{k},\dots),s)\downarrow=i_s.\end{align*}$$
Now, if
 $i_s=i_{s-1}=0$
or
$i_s=i_{s-1}=0$
or
 $s=0$
, then let
$s=0$
, then let
 $a^{s}_j=c_j$
for all
$a^{s}_j=c_j$
for all
 $j>k$
. Otherwise, for all
$j>k$
. Otherwise, for all
 $j>k$
, with
$j>k$
, with
 $c_j\neq \emptyset $
or
$c_j\neq \emptyset $
or
 $j\leq i_0$
, let
$j\leq i_0$
, let
 $a^s_j$
be
$a^s_j$
be
 $b_{n_j}$
where
$b_{n_j}$
where
 $n_j$
is such that
$n_j$
is such that
 $c_j=y\operatorname {\mathrm {\upharpoonright }} n_j$
. Notice that there are only finitely many
$c_j=y\operatorname {\mathrm {\upharpoonright }} n_j$
. Notice that there are only finitely many
 $c_j\neq \emptyset $
as
$c_j\neq \emptyset $
as
 $L(-,-,s)$
is continuous and the sequence
$L(-,-,s)$
is continuous and the sequence
 $(c_k,\dots )$
was lexicographical minimal. This finishes the description.
$(c_k,\dots )$
was lexicographical minimal. This finishes the description.
Say that
 $a_i=\lim _{s} a^s_i$
for all i, and consider
$a_i=\lim _{s} a^s_i$
for all i, and consider
 $L(y,(z,a_0,\dots ))$
. We claim that
$L(y,(z,a_0,\dots ))$
. We claim that
 $\lim _s L(y,(z,a_0,\dots ),s)=0$
if and only if
$\lim _s L(y,(z,a_0,\dots ),s)=0$
if and only if
 $z\in [y]_{E}=[x]_E$
. Suppose
$z\in [y]_{E}=[x]_E$
. Suppose
 $z\in [y]_{\mathrel {E}}$
, then there is a least stage
$z\in [y]_{\mathrel {E}}$
, then there is a least stage
 $s_0$
such that for all
$s_0$
such that for all
 $s>s_0$
,
$s>s_0$
,
 $L(y,(z,a_0,\dots ),s)=i$
implies
$L(y,(z,a_0,\dots ),s)=i$
implies
 $a_i\mathrel {E} y$
. Suppose that at stage
$a_i\mathrel {E} y$
. Suppose that at stage
 $s_1>s_0$
, the learner outputs
$s_1>s_0$
, the learner outputs
 $i\neq 0$
. Then at stage
$i\neq 0$
. Then at stage
 $s_1+1$
, we declare
$s_1+1$
, we declare
 $a_i=b_n\not \in [y]_{\mathrel {E}}$
contradicting the learnability of
$a_i=b_n\not \in [y]_{\mathrel {E}}$
contradicting the learnability of
 $\mathrel {E}$
. On the other hand, if
$\mathrel {E}$
. On the other hand, if
 $\lim _s L(y,(z,a_0,\dots ),s)=0$
, then there is a least
$\lim _s L(y,(z,a_0,\dots ),s)=0$
, then there is a least
 $s_0$
such that for all
$s_0$
such that for all
 $s>s_0$
,
$s>s_0$
,
 $L(y,(z,a_0,\dots ),s)=0$
. Hence, for some large enough t,
$L(y,(z,a_0,\dots ),s)=0$
. Hence, for some large enough t,
 $a_t=y$
and thus
$a_t=y$
and thus
 $z\in [y]_E$
.
$z\in [y]_E$
.
To see that
 $[x]_E$
is
$[x]_E$
is
 $\boldsymbol {\Sigma }^0_2$
, let R be the binary predicate recursive in
$\boldsymbol {\Sigma }^0_2$
, let R be the binary predicate recursive in
 $y\oplus \bigoplus b_n$
such that
$y\oplus \bigoplus b_n$
such that
 $R(z,s)=i$
if and only if
$R(z,s)=i$
if and only if
 $L(y,(z,a^0_s,\dots ),s)=i$
. Then
$L(y,(z,a^0_s,\dots ),s)=i$
. Then
 $z\in [x]_E$
if and only if
$z\in [x]_E$
if and only if
 $\exists m(\forall n>m) R(z,n)=0$
.
$\exists m(\forall n>m) R(z,n)=0$
.
The definition of the
 $\mathrel {E}$
-classes in Lemma 9 is inherently non-uniform. We proceed by showing that for all but countably many classes we can obtain a uniform definition, thus obtaining that
$\mathrel {E}$
-classes in Lemma 9 is inherently non-uniform. We proceed by showing that for all but countably many classes we can obtain a uniform definition, thus obtaining that
 $\mathrel {E}$
is Borel.
$\mathrel {E}$
is Borel.
Lemma 10. Let
 $\mathrel {E}$
be
$\mathrel {E}$
be
 $\mathsf {BC}$
-learnable, then
$\mathsf {BC}$
-learnable, then
 $\mathrel {E}$
is Borel.
$\mathrel {E}$
is Borel.
Proof. Suppose that
 $\mathrel {E}$
is an equivalence relation on
$\mathrel {E}$
is an equivalence relation on
 $2^\omega $
. Then there are only countably many classes that have non-empty interior and only countably many classes that contain elements with only finitely many non-zero bits. We call these classes exceptional as those are the classes for which we will need non-uniform definitions.
$2^\omega $
. Then there are only countably many classes that have non-empty interior and only countably many classes that contain elements with only finitely many non-zero bits. We call these classes exceptional as those are the classes for which we will need non-uniform definitions.
Let
 $[x]_E$
be a non-exceptional class, then the procedure given in Lemma 9 can be turned uniform by choosing
$[x]_E$
be a non-exceptional class, then the procedure given in Lemma 9 can be turned uniform by choosing
 $y=x$
and
$y=x$
and
 $b_n=(x\operatorname {\mathrm {\upharpoonright }} n)^\smallfrown 0^\infty $
. Hence, we can modify the recursive binary predicate given in the proof of Lemma 9 to obtain a recursive ternary predicate
$b_n=(x\operatorname {\mathrm {\upharpoonright }} n)^\smallfrown 0^\infty $
. Hence, we can modify the recursive binary predicate given in the proof of Lemma 9 to obtain a recursive ternary predicate
 $R'$
so that for
$R'$
so that for
 $x,y$
in a non-exceptional class,
$x,y$
in a non-exceptional class,
 $x\mathrel {E} y$
if and only if the procedure from Lemma 9 returns
$x\mathrel {E} y$
if and only if the procedure from Lemma 9 returns
 $0$
in the limit on x and y, i.e.,
$0$
in the limit on x and y, i.e.,
 $$\begin{align*}x\mathrel{E} y \iff \exists m(\forall n>m) R'(x,y,n)=0.\end{align*}$$
$$\begin{align*}x\mathrel{E} y \iff \exists m(\forall n>m) R'(x,y,n)=0.\end{align*}$$
To see that
 $\mathrel {E}$
is Borel note that
$\mathrel {E}$
is Borel note that
 $x\mathrel {E} y$
if and only if x and y are in the same exceptional class or neither are exceptional and
$x\mathrel {E} y$
if and only if x and y are in the same exceptional class or neither are exceptional and
 $x\mathrel {E} y$
via the procedure
$x\mathrel {E} y$
via the procedure
 $R'$
. This gives a Borel definition as required.
$R'$
. This gives a Borel definition as required.
While the definition given in Lemma 10 is Borel it is not
 $\boldsymbol {\Sigma }^0_2$
, as saying that neither class is exceptional is
$\boldsymbol {\Sigma }^0_2$
, as saying that neither class is exceptional is
 $\boldsymbol {\Pi }^0_2$
. However, combining Lemma 10 with recent results of Lecomte [Reference Lecomte13] we are now ready to show that the
$\boldsymbol {\Pi }^0_2$
. However, combining Lemma 10 with recent results of Lecomte [Reference Lecomte13] we are now ready to show that the
 $\mathsf {BC}$
-learnable and learnable equivalence relations are the same.
$\mathsf {BC}$
-learnable and learnable equivalence relations are the same.
Theorem 11. An equivalence relation E is
 $\mathsf {BC}$
-learnable if and only if E is learnable if and only if E is
$\mathsf {BC}$
-learnable if and only if E is learnable if and only if E is
 $\boldsymbol {\Sigma }^0_2$
.
$\boldsymbol {\Sigma }^0_2$
.
Lecomte [Reference Lecomte13] exhibited a finite set of non
 $\boldsymbol {\Sigma }^0_2$
equivalence relations that are minimal and form an antichain under continuous reducibility. Furthermore, every Borel equivalence relation that is not
$\boldsymbol {\Sigma }^0_2$
equivalence relations that are minimal and form an antichain under continuous reducibility. Furthermore, every Borel equivalence relation that is not
 $\boldsymbol {\Sigma }^0_2$
continuously embeds one of these relations. Our proof of Theorem 11 will show that none of Lecomte’s relations are
$\boldsymbol {\Sigma }^0_2$
continuously embeds one of these relations. Our proof of Theorem 11 will show that none of Lecomte’s relations are
 $\mathsf {BC}$
-learnable. Before we proceed with the proof let us recall Lecomte’s result in more detail.
$\mathsf {BC}$
-learnable. Before we proceed with the proof let us recall Lecomte’s result in more detail.
The five equivalence relations can be defined as follows. Let
 $\mathrm {INF}$
refer to the class of characteristic functions of all infinite subsets of
$\mathrm {INF}$
refer to the class of characteristic functions of all infinite subsets of
 $\omega $
. That is,
$\omega $
. That is,
 $\mathrm {INF}=\{x\in 2^{\omega }:\forall n (\exists m>n) x(m)=1\}$
. All the relations below are defined on
$\mathrm {INF}=\{x\in 2^{\omega }:\forall n (\exists m>n) x(m)=1\}$
. All the relations below are defined on
 $2^\omega $
.
$2^\omega $
.
-
•
$x \mathbin {\sim _0} y\iff (x,y\in \mathrm {INF}) \vee (x=y)$
-
•
$ x \mathbin {\sim _1} y\iff (x,y\in \mathrm {INF}) \vee (x,y\notin \mathrm {INF})$
-
•
$ x \mathbin {\sim _3} y\iff (x=y) \vee (x,y\in \mathrm {INF} \land (\forall n>0) x(n)=y(n))$
-
•
$ x \mathbin {\sim _4} y\iff x \mathbin {\sim _3} y \vee (x(0)=y(0)=1\wedge x,y\notin \mathrm {INF})$
-
•
$ x \mathbin {\sim _5} y\iff x \mathbin {\sim _3} y \vee (x(0)=y(0)\wedge x,y\notin \mathrm {INF}).$





Theorem 12 (Lecomte [Reference Lecomte13])
Let
 $\mathrel {E}$
be a Borel equivalence relation. Then exactly one of the following holds:
$\mathrel {E}$
be a Borel equivalence relation. Then exactly one of the following holds:
-
•
$\mathrel {E}$
is
$\boldsymbol {\Sigma }^0_2$
. -
• there is
$i\in \{0,1,3,4,5\}$
and an injective continuous reduction from
$\sim _i$
to
$\mathrel {E}$
.





Proof of Theorem 11
Since by definition every learnable equivalence relation is also
 $\mathsf {BC}$
-learnable, we only have to deal with the other implication. Our proof proceeds by showing that each of Lecomte’s equivalence relations is not
$\mathsf {BC}$
-learnable, we only have to deal with the other implication. Our proof proceeds by showing that each of Lecomte’s equivalence relations is not
 $\mathsf {BC}$
-learnable. Since
$\mathsf {BC}$
-learnable. Since
 $\mathsf {BC}$
-learnability is preserved by continuous reductions, this implies that the
$\mathsf {BC}$
-learnability is preserved by continuous reductions, this implies that the
 $\mathsf {BC}$
-learnable Borel equivalence relations are precisely the learnable Borel equivalence relations. Using Lemma 10 we can then infer Theorem 11 in its full generality.
$\mathsf {BC}$
-learnable Borel equivalence relations are precisely the learnable Borel equivalence relations. Using Lemma 10 we can then infer Theorem 11 in its full generality.
It remains to show that none of the
 $\sim _i$
,
$\sim _i$
,
 $i\in \{0,1,3,4,5\}$
are
$i\in \{0,1,3,4,5\}$
are
 $\mathsf {BC}$
-learnable. In all five cases, we achieve that by exploiting the fact that
$\mathsf {BC}$
-learnable. In all five cases, we achieve that by exploiting the fact that
 $\mathrm {INF}$
has no
$\mathrm {INF}$
has no
 $\boldsymbol {\Sigma }^0_2$
definition. The argument are analogous. We assume that
$\boldsymbol {\Sigma }^0_2$
definition. The argument are analogous. We assume that
 $\sim _i$
is
$\sim _i$
is
 $\mathsf {BC}$
-learnable and use this assumption to obtain a
$\mathsf {BC}$
-learnable and use this assumption to obtain a
 $\boldsymbol {\Sigma }^0_2$
definition of
$\boldsymbol {\Sigma }^0_2$
definition of
 $\mathrm {INF}$
, which gives a contradiction.
$\mathrm {INF}$
, which gives a contradiction.
Suppose that
 $\sim _0$
is
$\sim _0$
is
 $\mathsf {BC}$
-learnable by L. We claim that the following is a
$\mathsf {BC}$
-learnable by L. We claim that the following is a
 $\boldsymbol {\Sigma }^0_2$
definition of
$\boldsymbol {\Sigma }^0_2$
definition of
 $\mathrm {INF}$
:
$\mathrm {INF}$
:
 $$\begin{align*}x\in \mathrm{INF}\iff\exists m (\forall n>m) L(x,(1^{\infty},f_1,f_2,\ldots),n)=0.\end{align*}$$
$$\begin{align*}x\in \mathrm{INF}\iff\exists m (\forall n>m) L(x,(1^{\infty},f_1,f_2,\ldots),n)=0.\end{align*}$$
where
 $f_1,f_2,\ldots $
is an enumeration of all elements of
$f_1,f_2,\ldots $
is an enumeration of all elements of
 $2^{\omega }$
with finitely many ones. Note that x is either finite and identical to some
$2^{\omega }$
with finitely many ones. Note that x is either finite and identical to some
 $f_i$
, or infinite and
$f_i$
, or infinite and
 $\sim _0$
-equivalent to
$\sim _0$
-equivalent to
 $1^{\infty }$
. Hence, if L is a
$1^{\infty }$
. Hence, if L is a
 $\mathsf {BC}$
-learner for
$\mathsf {BC}$
-learner for
 $\sim _0$
, then L converges on
$\sim _0$
, then L converges on
 $0$
if x is infinite and to some
$0$
if x is infinite and to some
 $k\neq 0$
otherwise. A similar argument shows that the above formula gives a
$k\neq 0$
otherwise. A similar argument shows that the above formula gives a
 $\boldsymbol {\Sigma }^0_2$
definition for
$\boldsymbol {\Sigma }^0_2$
definition for
 $\sim _1$
if we assume that L is a
$\sim _1$
if we assume that L is a
 $\mathsf {BC}$
-learner for
$\mathsf {BC}$
-learner for
 $\sim _1$
.
$\sim _1$
.
Similarly, if we assume that L is a
 $\mathsf {BC}$
-learner for
$\mathsf {BC}$
-learner for
 $\sim _i$
,
$\sim _i$
,
 $3\leq i\leq 5$
, then the following formula gives a
$3\leq i\leq 5$
, then the following formula gives a
 $\boldsymbol {\Sigma }^0_2$
definition of
$\boldsymbol {\Sigma }^0_2$
definition of
 $\mathrm {INF}$
:
$\mathrm {INF}$
:
 $$\begin{align*}x\in \mathrm{INF}\iff \exists m (\forall n>m)L(0x,(1x,0f_1,0f_2,\ldots),n)=0.\\[-34pt]\end{align*}$$
$$\begin{align*}x\in \mathrm{INF}\iff \exists m (\forall n>m)L(0x,(1x,0f_1,0f_2,\ldots),n)=0.\\[-34pt]\end{align*}$$
2.4 Borel learnability
In modern descriptive set theory Borel functions arguably play a more prominent role than continuous functions. The reason for this is the following classical change of topology theorem. If
 $f:(X,\sigma )\to Y$
is Borel, then there is a Polish topology
$f:(X,\sigma )\to Y$
is Borel, then there is a Polish topology
 $\tau \supset \sigma $
such that the Borel sets generated by
$\tau \supset \sigma $
such that the Borel sets generated by
 $\tau $
and
$\tau $
and
 $\sigma $
are the same and
$\sigma $
are the same and
 $f:(X,\tau )\to Y$
is continuous; see [Reference Kechris11, Chapter 13] for a proof.
$f:(X,\tau )\to Y$
is continuous; see [Reference Kechris11, Chapter 13] for a proof.
The following modification of uniform learnability might thus look more natural to a descriptive set theorist.
Definition 6. Let E be an equivalence relation on a Polish space X and assume
 $\omega $
is equipped with the discrete topology. We say that E is Borel learnable, if there are Borel functions
$\omega $
is equipped with the discrete topology. We say that E is Borel learnable, if there are Borel functions
 $l_n: X^\omega \times X\to \omega $
such that for
$l_n: X^\omega \times X\to \omega $
such that for
 $x\in X$
and
$x\in X$
and
 $\vec x=(x_i)_{i\in \omega }\in X^\omega $
, if
$\vec x=(x_i)_{i\in \omega }\in X^\omega $
, if
 $x\mathrel {E} x_i$
for some
$x\mathrel {E} x_i$
for some
 $i\in \omega $
, then
$i\in \omega $
, then
 $L(\vec x,x)=\lim l_n(\vec x, x)$
exists and
$L(\vec x,x)=\lim l_n(\vec x, x)$
exists and
 $x \mathrel {E} x_{L(\vec x,x)}$
. We refer to the partial function L as a Borel learner for E.
$x \mathrel {E} x_{L(\vec x,x)}$
. We refer to the partial function L as a Borel learner for E.
Combining the above change of topology theorem with the boldface version of Theorem 6 we immediately obtain that an equivalence relation E on a Polish space
 $(X,\sigma )$
is Borel learnable if and only if there is
$(X,\sigma )$
is Borel learnable if and only if there is
 $\tau \supseteq \sigma $
such that E is
$\tau \supseteq \sigma $
such that E is
 $\boldsymbol {\Sigma }^0_2$
in
$\boldsymbol {\Sigma }^0_2$
in
 $(X,\tau )^2$
. Following Louveau [Reference Louveau15], we say that such an equivalence relation is potentially
$(X,\tau )^2$
. Following Louveau [Reference Louveau15], we say that such an equivalence relation is potentially
 $\boldsymbol {\Sigma }^0_2$
and thus get the following.
$\boldsymbol {\Sigma }^0_2$
and thus get the following.
Theorem 13. An equivalence relation E is Borel learnable if and only if E is potentially
 $\boldsymbol {\Sigma }^0_2$
.
$\boldsymbol {\Sigma }^0_2$
.
One can also consider the notion of non-uniform Borel learnability by adapting Definition 1 in the obvious way. We then get the following from another classical change of topology theorem.
Proposition 14. Let
 $\mathrel {E}$
be an equivalence relation on a Polish space X. Then the following are equivalent.
$\mathrel {E}$
be an equivalence relation on a Polish space X. Then the following are equivalent.
-
(1)
$\mathrel {E}$
is non-uniformly Borel learnable. -
(2) For every
$\vec x\in X^\omega $
, there are sets
$S_i$
,
$S_i\in Borel(X)$
such that for every
$i\in \omega $
,
$[x_i]_E\subseteq S_i$
and
$S_i\cap S_j=\emptyset $
if
$x_i\not\!\! {\mathrel {E}} x_j$
.

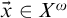






Furthermore,
 $\mathrel {E}$
is non-uniformly learnable by learners not giving false positives if and only if
$\mathrel {E}$
is non-uniformly learnable by learners not giving false positives if and only if
 $[x]$
is Borel for every
$[x]$
is Borel for every
 $x\in X$
.
$x\in X$
.
Proof. Suppose we have a learner L learning
 $\vec x\in X^\omega $
. Using the change of topology theorem mentioned above, we get a topology
$\vec x\in X^\omega $
. Using the change of topology theorem mentioned above, we get a topology
 $\tau $
on X such that the learner L is continuous. Hence, by Proposition 1, there are
$\tau $
on X such that the learner L is continuous. Hence, by Proposition 1, there are
 $(S_i)_{i\in \omega }$
separating the equivalence classes
$(S_i)_{i\in \omega }$
separating the equivalence classes
 $[x_i]_E$
such that every
$[x_i]_E$
such that every
 $S_i$
is
$S_i$
is
 $\boldsymbol {\Sigma }^0_2$
in
$\boldsymbol {\Sigma }^0_2$
in
 $\tau $
. But then as the Borel sets in
$\tau $
. But then as the Borel sets in
 $\tau $
and the original topology are the same, the
$\tau $
and the original topology are the same, the
 $S_i$
are Borel in the original topology on X.
$S_i$
are Borel in the original topology on X.
On the other hand, recall another classical change of topology theorem: If
 $(A_i)_{i\in \omega }$
is a countable sequence of Borel sets on X, then there is a refinement
$(A_i)_{i\in \omega }$
is a countable sequence of Borel sets on X, then there is a refinement
 $\tau $
of X generating the same Borel sets, such that every
$\tau $
of X generating the same Borel sets, such that every
 $A_i$
is clopen, see again [Reference Kechris11, Chapter 13]. Hence, given
$A_i$
is clopen, see again [Reference Kechris11, Chapter 13]. Hence, given
 $S_i$
as in Item 2 we get a topology
$S_i$
as in Item 2 we get a topology
 $\tau $
with all
$\tau $
with all
 $S_i$
clopen and a learner L for
$S_i$
clopen and a learner L for
 $\vec x$
that is
$\vec x$
that is
 $\tau $
-continuous, and hence Borel.
$\tau $
-continuous, and hence Borel.
3 Complexity of learnability
For the proofs of the following results, we rely on Louveau’s separation theorem and the Spector–Gandy theorem. Recall that
 $\mathrm {HYP}$
denotes the hyperarithmetic, or equivalently
$\mathrm {HYP}$
denotes the hyperarithmetic, or equivalently
 $\Delta ^1_1$
, subsets of the natural numbers. We say that Y is a
$\Delta ^1_1$
, subsets of the natural numbers. We say that Y is a
 $\Sigma ^0_\alpha (\mathrm {HYP})$
subset of a recursive Polish space X if there is
$\Sigma ^0_\alpha (\mathrm {HYP})$
subset of a recursive Polish space X if there is
 $x\in \mathrm {HYP}$
such that
$x\in \mathrm {HYP}$
such that
 $Y\in \Sigma ^0_\alpha (x)$
. Louveau’s separation theorem says that if X is a recursive Polish space and
$Y\in \Sigma ^0_\alpha (x)$
. Louveau’s separation theorem says that if X is a recursive Polish space and
 $A_0,A_1$
are two disjoint
$A_0,A_1$
are two disjoint
 $\Sigma ^1_1$
sets that are
$\Sigma ^1_1$
sets that are
 $\boldsymbol {\Sigma }^0_\alpha $
separated for a recursive ordinal
$\boldsymbol {\Sigma }^0_\alpha $
separated for a recursive ordinal
 $\alpha $
, then there is a
$\alpha $
, then there is a
 $\Sigma ^0_\alpha (\mathrm {HYP})$
set separating
$\Sigma ^0_\alpha (\mathrm {HYP})$
set separating
 $A_0$
from
$A_0$
from
 $A_1$
[Reference Louveau14]. In particular, if X is
$A_1$
[Reference Louveau14]. In particular, if X is
 $\Delta ^1_1$
and
$\Delta ^1_1$
and
 $\boldsymbol {\Sigma }^0_\alpha $
, then X is
$\boldsymbol {\Sigma }^0_\alpha $
, then X is
 $\Sigma ^0_\alpha (\mathrm {HYP})$
. To see this, just take
$\Sigma ^0_\alpha (\mathrm {HYP})$
. To see this, just take
 $A_0=X$
and
$A_0=X$
and
 $A_1=\bar X$
.
$A_1=\bar X$
.
We will combine this with the classic Spector–Gandy theorem. The version most suitable for our purpose says that a set
 $X\subseteq 2^\omega $
is
$X\subseteq 2^\omega $
is
 $\Pi ^1_1$
if and only if there is a recursive predicate R such that
$\Pi ^1_1$
if and only if there is a recursive predicate R such that
 $$\begin{align*}x\in X \iff (\exists z \in \Delta^1_1( x))R(x,z).\end{align*}$$
$$\begin{align*}x\in X \iff (\exists z \in \Delta^1_1( x))R(x,z).\end{align*}$$
We suggest [Reference Chong and Yu4] for a detailed discussion of this theorem. The following result is a consequence of Louveau’s separation theorem and Theorem 6.
Lemma 15. Let E be a learnable
 $\Delta ^1_1$
equivalence relation. Then there is a hyperarithmetical learner learning E.
$\Delta ^1_1$
equivalence relation. Then there is a hyperarithmetical learner learning E.
Proof. Recall from Theorem 6 that an equivalence relation is learnable by an x-computable learner if and only if it is
 $\Sigma ^0_2(x)$
. Now by Louveau’s separation theorem
$\Sigma ^0_2(x)$
. Now by Louveau’s separation theorem
 $\Delta ^1_1 \cap \boldsymbol {\Sigma }^0_2=\Sigma ^0_2(\mathrm {HYP})$
. Thus E being learnable and
$\Delta ^1_1 \cap \boldsymbol {\Sigma }^0_2=\Sigma ^0_2(\mathrm {HYP})$
. Thus E being learnable and
 $\Delta ^1_1$
implies that E is
$\Delta ^1_1$
implies that E is
 $\Sigma ^0_2(\mathrm {HYP})$
and so it is learnable by a hyperarithmetical learner.
$\Sigma ^0_2(\mathrm {HYP})$
and so it is learnable by a hyperarithmetical learner.
We can represent Borel equivalence relations on a Polish space X using their Borel codes. Recall that a Borel code is a labeled tree
 $T\in \omega ^{<\omega }$
where the leaf nodes are labeled by (the codes) for elements of a fixed subbase of X and internal nodes are labeled by
$T\in \omega ^{<\omega }$
where the leaf nodes are labeled by (the codes) for elements of a fixed subbase of X and internal nodes are labeled by
 $\cup $
or
$\cup $
or
 $\cap $
, indicating that we take unions or intersections of the sets described by the subtree rooted at that node. We can view labeled trees as elements of
$\cap $
, indicating that we take unions or intersections of the sets described by the subtree rooted at that node. We can view labeled trees as elements of
 $2^\omega $
and thus can talk about the complexity of the set of Borel equivalence relations with some property P. As every learnable equivalence relation is Borel by Theorem 6 we can talk about the complexity of learnable equivalence relations in the codes.
$2^\omega $
and thus can talk about the complexity of the set of Borel equivalence relations with some property P. As every learnable equivalence relation is Borel by Theorem 6 we can talk about the complexity of learnable equivalence relations in the codes.
Theorem 16. The set of learnable equivalence relations on Cantor space is
 $\Pi ^1_1$
in the codes.
$\Pi ^1_1$
in the codes.
Proof. Note that T is a code for a learnable equivalence relation if and only if (1) T is well-founded, (2) its labeling is correct, and (3) there is a learner learning E, the equivalence relation represented by T. The first statement is
 $\Pi ^1_1$
, the second arithmetical, and by the relativization of Lemma 15, we have that E is learnable if and only if there exists a learner hyperarithmetic in T. By the Spector-Gandy theorem this is a
$\Pi ^1_1$
, the second arithmetical, and by the relativization of Lemma 15, we have that E is learnable if and only if there exists a learner hyperarithmetic in T. By the Spector-Gandy theorem this is a
 $\Pi ^1_1$
statement.
$\Pi ^1_1$
statement.
We will establish that the set of learnable Borel equivalence relations on Cantor space is
 $\boldsymbol {\Pi }^1_1$
-complete in the codes. Let us quickly recall the definitions. Let X and Y be Polish spaces, and
$\boldsymbol {\Pi }^1_1$
-complete in the codes. Let us quickly recall the definitions. Let X and Y be Polish spaces, and
 $A\subseteq X$
,
$A\subseteq X$
,
 $B\subseteq Y$
. Then A is Wadge reducible to B,
$B\subseteq Y$
. Then A is Wadge reducible to B,
 $A\leq _W B$
if there exists a continuous function
$A\leq _W B$
if there exists a continuous function
 $f:X\to Y$
such that for all
$f:X\to Y$
such that for all
 $x\in X$
,
$x\in X$
,
 $x\in A$
if and only
$x\in A$
if and only
 $f(x)\in B$
. For a pointclass class
$f(x)\in B$
. For a pointclass class
 $\pmb \Gamma $
, and
$\pmb \Gamma $
, and
 $A\in \pmb \Gamma $
, A is
$A\in \pmb \Gamma $
, A is
 $\pmb \Gamma $
-complete if for every
$\pmb \Gamma $
-complete if for every
 $B\in \pmb \Gamma $
,
$B\in \pmb \Gamma $
,
 $B\leq _W A$
. We are now ready to pin down the complexity of the learnable Borel equivalence relations.
$B\leq _W A$
. We are now ready to pin down the complexity of the learnable Borel equivalence relations.
Theorem 17. The set of learnable
 $\boldsymbol {\Pi }^0_2$
equivalence relations on Cantor space is
$\boldsymbol {\Pi }^0_2$
equivalence relations on Cantor space is
 $\boldsymbol {\Pi }^1_1$
-complete in the codes.
$\boldsymbol {\Pi }^1_1$
-complete in the codes.
Proof. Recall that the set of well-founded trees in
 $\omega ^{<\omega }$
is
$\omega ^{<\omega }$
is
 $\boldsymbol {\Pi }^1_1$
-complete. We reduce it to the set of codes of learnable
$\boldsymbol {\Pi }^1_1$
-complete. We reduce it to the set of codes of learnable
 $\boldsymbol {\Pi }^0_2$
equivalence relations as follows. Given
$\boldsymbol {\Pi }^0_2$
equivalence relations as follows. Given
 $x\in 2^\omega $
we might view it as a disjoint union
$x\in 2^\omega $
we might view it as a disjoint union
 $x=x_1\oplus x_2$
where
$x=x_1\oplus x_2$
where
 $x_1(n)=x(2n)$
and
$x_1(n)=x(2n)$
and
 $x_2(n)=x(2n+1)$
. We furthermore write
$x_2(n)=x(2n+1)$
. We furthermore write
 $p_x$
for the principal function of x, that is the function enumerating the set of natural numbers defined by x in order. Notice that
$p_x$
for the principal function of x, that is the function enumerating the set of natural numbers defined by x in order. Notice that
 $p_x\in \omega ^\omega $
if and only if x is infinite, and thus this is already a
$p_x\in \omega ^\omega $
if and only if x is infinite, and thus this is already a
 $\Pi ^0_2$
statement. Also recall that the set
$\Pi ^0_2$
statement. Also recall that the set
 $\mathrm {INF}=\{\chi _X: X\subseteq \omega , |X|=\infty \}$
is
$\mathrm {INF}=\{\chi _X: X\subseteq \omega , |X|=\infty \}$
is
 $\boldsymbol {\Pi }^0_2$
-complete. We are now ready to define our reduction. Given a tree
$\boldsymbol {\Pi }^0_2$
-complete. We are now ready to define our reduction. Given a tree
 $T\subseteq \omega ^{<\omega }$
define a
$T\subseteq \omega ^{<\omega }$
define a
 $\Pi ^0_2$
equivalence relation
$\Pi ^0_2$
equivalence relation
 $E_T$
by
$E_T$
by
 $$\begin{align*}x\mathbin{E_T} y\iff x=y \lor\left(p_{x_1},p_{y_1}\in [T] \land x_2,y_2\in\mathrm{INF}\right).\end{align*}$$
$$\begin{align*}x\mathbin{E_T} y\iff x=y \lor\left(p_{x_1},p_{y_1}\in [T] \land x_2,y_2\in\mathrm{INF}\right).\end{align*}$$
Notice that if T is well-founded, then
 $E_T=id_{2^\omega }$
. On the other hand, if T is ill-founded, then we claim that
$E_T=id_{2^\omega }$
. On the other hand, if T is ill-founded, then we claim that
 $E_T$
is not learnable. Fix
$E_T$
is not learnable. Fix
 $x\in [T]$
, and consider
$x\in [T]$
, and consider
 $[\langle x,1^\infty \rangle ]_{E_T}$
, the equivalence class of
$[\langle x,1^\infty \rangle ]_{E_T}$
, the equivalence class of
 $\langle x, 1^\infty \rangle $
. If
$\langle x, 1^\infty \rangle $
. If
 $E_T$
were learnable, then by Theorem 13,
$E_T$
were learnable, then by Theorem 13,
 $[\langle x,1^\infty \rangle ]_{E_T}$
would be
$[\langle x,1^\infty \rangle ]_{E_T}$
would be
 $\Sigma ^0_2(x)$
. But then as
$\Sigma ^0_2(x)$
. But then as
 $$\begin{align*}y\in \mathrm{INF} \iff \langle x,y\rangle\in [\langle x,1^\infty\rangle]_{E_T}\end{align*}$$
$$\begin{align*}y\in \mathrm{INF} \iff \langle x,y\rangle\in [\langle x,1^\infty\rangle]_{E_T}\end{align*}$$
we would get that
 $\mathrm {INF}$
is
$\mathrm {INF}$
is
 $\Sigma ^0_2(x)$
, a contradiction. Thus, the function
$\Sigma ^0_2(x)$
, a contradiction. Thus, the function
 $T\mapsto E_T$
is a continuous reduction from the set of well-founded trees to the set of codes of
$T\mapsto E_T$
is a continuous reduction from the set of well-founded trees to the set of codes of
 $\boldsymbol {\Pi }^0_2$
equivalence relations that are learnable.
$\boldsymbol {\Pi }^0_2$
equivalence relations that are learnable.
Since the equivalence relation
 $E_T$
produced in the above proof is
$E_T$
produced in the above proof is
 $id_{2^\omega }$
if T is well-founded, and this equivalence relation is learnable by a computable learner, we obtain the following effective analog to Theorem 17.
$id_{2^\omega }$
if T is well-founded, and this equivalence relation is learnable by a computable learner, we obtain the following effective analog to Theorem 17.
Corollary 18. The set of
 $\boldsymbol {\Pi }^0_2$
equivalence relations that are learnable by a computable learner is
$\boldsymbol {\Pi }^0_2$
equivalence relations that are learnable by a computable learner is
 $\boldsymbol {\Pi }^1_1$
-complete in the codes.
$\boldsymbol {\Pi }^1_1$
-complete in the codes.
Theorems 16 and 17 directly imply the following result.
Corollary 19. The set of learnable equivalence relations is
 $\boldsymbol {\Pi }^1_1$
-complete in the codes.
$\boldsymbol {\Pi }^1_1$
-complete in the codes.
Using the recursion theorem to identify computable codes for Borel equivalence relations with their indices and noticing that given a computable tree T we produce a computable Borel code for
 $E_T$
we get similar results for the index sets of codes for learnable equivalence relations.
$E_T$
we get similar results for the index sets of codes for learnable equivalence relations.
Corollary 20.
-
(1) The set of indices of codes for learnable equivalence relations is
$\Pi ^1_1$
-complete. -
(2) The set of indices of codes for equivalence relations learnable by a computable learner is
$\Pi ^1_1$
-complete.


4 Case study
In this section, we study whether various equivalence relations arising in logic are learnable, and, since learnability is closely tied to the Borel hierarchy, place these equivalence relations in this hierarchy.
4.1 Equivalence relations arising in computability theory
Theorem 21. Turing equivalence is not learnable. In fact, it is not
 $\boldsymbol {\Pi }^0_3$
.Footnote
1
$\boldsymbol {\Pi }^0_3$
.Footnote
1
Proof. Assume towards a contradiction that
 $\equiv _T$
is
$\equiv _T$
is
 $\Pi ^0_3(a)$
for
$\Pi ^0_3(a)$
for
 $a\in 2^\omega $
. That is, suppose that there is a
$a\in 2^\omega $
. That is, suppose that there is a
 $\Pi ^0_3$
formula
$\Pi ^0_3$
formula
 $$\begin{align*}\psi(x,y,z)= \forall k\exists m\forall n R(z,x,y,k,m,n)\end{align*}$$
$$\begin{align*}\psi(x,y,z)= \forall k\exists m\forall n R(z,x,y,k,m,n)\end{align*}$$
where R is a recursive relation and
 $\psi (x,y,a)$
holds if and only if
$\psi (x,y,a)$
holds if and only if
 $x\equiv _T y$
. It is not hard to see that it is dense in the product forcing
$x\equiv _T y$
. It is not hard to see that it is dense in the product forcing
 $\mathbb P^2$
that
$\mathbb P^2$
that
 $a\oplus \dot g_i\not \geq _T a\oplus \dot g_{1-i}$
for
$a\oplus \dot g_i\not \geq _T a\oplus \dot g_{1-i}$
for
 $i<2$
. Thus, if we consider a sufficiently mutual generic pair
$i<2$
. Thus, if we consider a sufficiently mutual generic pair
 $g_1,g_2$
relative to a, then
$g_1,g_2$
relative to a, then
 $a\oplus g_1,a\oplus g_2$
are not Turing equivalent and so there is
$a\oplus g_1,a\oplus g_2$
are not Turing equivalent and so there is
 $(p_1,p_2)$
such that
$(p_1,p_2)$
such that
 $(p_1,p_2)\Vdash \exists k \forall m\exists n \neg R(a\oplus \dot g_1,a\oplus \dot g_2,a,k,m,n)$
. In particular, there is
$(p_1,p_2)\Vdash \exists k \forall m\exists n \neg R(a\oplus \dot g_1,a\oplus \dot g_2,a,k,m,n)$
. In particular, there is
 $k_1$
such that the set
$k_1$
such that the set
 $$\begin{align*}Q=\{(q_1,q_2): (q_1,q_2) \Vdash \forall m\exists n \neg R(a\oplus\dot g_1,a\oplus\dot g_2,a, k_1,m,n)\}\end{align*}$$
$$\begin{align*}Q=\{(q_1,q_2): (q_1,q_2) \Vdash \forall m\exists n \neg R(a\oplus\dot g_1,a\oplus\dot g_2,a, k_1,m,n)\}\end{align*}$$
is dense below
 $(p_1,p_2)$
. Using this fact we can build two a-recursive reals
$(p_1,p_2)$
. Using this fact we can build two a-recursive reals
 $(h_1,h_2)\succ (p_1,p_2)$
such that
$(h_1,h_2)\succ (p_1,p_2)$
such that
 $\neg \psi (a\oplus h_1,a\oplus h_2,a)$
. However, since they are a-recursive, clearly
$\neg \psi (a\oplus h_1,a\oplus h_2,a)$
. However, since they are a-recursive, clearly
 $h_1\oplus a\equiv _T h_2\oplus a\equiv _T a$
, contradicting that
$h_1\oplus a\equiv _T h_2\oplus a\equiv _T a$
, contradicting that
 $\psi (a)$
defines
$\psi (a)$
defines
 $\equiv _T$
. Thus, Turing equivalence cannot be
$\equiv _T$
. Thus, Turing equivalence cannot be
 $\boldsymbol {\Pi }^0_3$
-definable and so, by Theorem 6, it cannot be learnable.
$\boldsymbol {\Pi }^0_3$
-definable and so, by Theorem 6, it cannot be learnable.
It remains to build
 $h_1$
and
$h_1$
and
 $h_2$
. We do this in stages; say at stage s we have built the finite strings
$h_2$
. We do this in stages; say at stage s we have built the finite strings
 $h_1^s$
and
$h_1^s$
and
 $h_2^s$
. Let
$h_2^s$
. Let
 $h_1^{s+1}$
and
$h_1^{s+1}$
and
 $h_2^{s+1}$
be the lexicographical minimal pair
$h_2^{s+1}$
be the lexicographical minimal pair
 $(q_1,q_2)$
that extends
$(q_1,q_2)$
that extends
 $(h_1^s,h_2^s)$
and so that
$(h_1^s,h_2^s)$
and so that
 $(q_1,q_2)\Vdash \exists n \neg R(a\oplus \dot g_1,a\oplus \dot g_2,a,s,n)$
. We can always find such a pair as Q is dense below
$(q_1,q_2)\Vdash \exists n \neg R(a\oplus \dot g_1,a\oplus \dot g_2,a,s,n)$
. We can always find such a pair as Q is dense below
 $(p_1,p_2)$
and the search is a-recursive since by the definition of the strong forcing relation the existential quantifier must be witnessed by
$(p_1,p_2)$
and the search is a-recursive since by the definition of the strong forcing relation the existential quantifier must be witnessed by
 $n< \min \{|q_1|,|q_2|\}$
.
$n< \min \{|q_1|,|q_2|\}$
.
By Wadge’s lemma [Reference Wadge19] any set that is not
 $\boldsymbol {\Pi }^0_3$
is
$\boldsymbol {\Pi }^0_3$
is
 $\boldsymbol {\Sigma }^0_3$
-hard. Hence, we obtain the following corollary.
$\boldsymbol {\Sigma }^0_3$
-hard. Hence, we obtain the following corollary.
Corollary 22. Turing equivalence is
 $\boldsymbol {\Sigma }^0_3$
-complete.
$\boldsymbol {\Sigma }^0_3$
-complete.
Turing equivalence was a good candidate for being learnable, as it is naturally
 $\Sigma ^0_3$
. Coarser equivalence relations such as arithmetic equivalence or hyperarithmetic equivalence are quite far from being learnable. The former is not arithmetical and the latter is not even Borel. We assume that these results are well-known but let us quickly summarize the overall ideas needed to show this, which are quite similar to the ones used in Theorem 21.
$\Sigma ^0_3$
. Coarser equivalence relations such as arithmetic equivalence or hyperarithmetic equivalence are quite far from being learnable. The former is not arithmetical and the latter is not even Borel. We assume that these results are well-known but let us quickly summarize the overall ideas needed to show this, which are quite similar to the ones used in Theorem 21.
For arithmetic equivalence, assume it was
 $\Sigma ^0_n(x)$
for some
$\Sigma ^0_n(x)$
for some
 $n\in \omega $
and a real x. Then, in the product forcing, there is
$n\in \omega $
and a real x. Then, in the product forcing, there is
 $(p_1,p_2)$
such that every n-generic pair extending
$(p_1,p_2)$
such that every n-generic pair extending
 $(p_1,p_2)$
is not arithmetic equivalent. However, one can show that there are arithmetically equivalent n-generics, contradicting the above. The proof for hyperarithmetic equivalence is similar.
$(p_1,p_2)$
is not arithmetic equivalent. However, one can show that there are arithmetically equivalent n-generics, contradicting the above. The proof for hyperarithmetic equivalence is similar.
Let us now consider the equivalence relations of m and
 $1$
-equivalence. Recall that two reals x and y are m-equivalent,
$1$
-equivalence. Recall that two reals x and y are m-equivalent,
 $x\equiv _m y$
, if there exists a total computable function
$x\equiv _m y$
, if there exists a total computable function
 ${\varphi }_e$
such that
${\varphi }_e$
such that
 $x(n)=1$
if and only if
$x(n)=1$
if and only if
 $y({\varphi }_e(n))=1$
. The two reals x, y are
$y({\varphi }_e(n))=1$
. The two reals x, y are
 $1$
-equivalent,
$1$
-equivalent,
 $x\equiv _1 y$
, if
$x\equiv _1 y$
, if
 $x\equiv _m y$
via a 1-1 function. Both of these relations are naturally
$x\equiv _m y$
via a 1-1 function. Both of these relations are naturally
 $\Sigma ^0_3$
, m-equivalence being defined by
$\Sigma ^0_3$
, m-equivalence being defined by
 $$ \begin{align} x\equiv_m y \iff \exists e \ {\varphi}_e \text{ total} \land \forall n (x(n)\leftrightarrow y({\varphi}_e(n))) \end{align} $$
$$ \begin{align} x\equiv_m y \iff \exists e \ {\varphi}_e \text{ total} \land \forall n (x(n)\leftrightarrow y({\varphi}_e(n))) \end{align} $$
and
 $1$
-equivalence being defined analogously.
$1$
-equivalence being defined analogously.
Theorem 23. If
 $\mathrel {E}$
is an equivalence relation so that
$\mathrel {E}$
is an equivalence relation so that
 $\equiv _1\subseteq \mathrel {E}\subseteq \equiv _T$
, then
$\equiv _1\subseteq \mathrel {E}\subseteq \equiv _T$
, then
 $\mathrel {E}$
is not
$\mathrel {E}$
is not
 $\Pi ^0_3$
.
$\Pi ^0_3$
.
Proof. Suppose toward a contradiction that E is given by the
 $\Pi ^0_3$
formula
$\Pi ^0_3$
formula
 $$\begin{align*}{\varphi}(x,y) \iff \exists l\forall m\exists n R(x,y,l,m,n)\end{align*}$$
$$\begin{align*}{\varphi}(x,y) \iff \exists l\forall m\exists n R(x,y,l,m,n)\end{align*}$$
where R is a recursive relation. Then
 ${\varphi }(\dot g_1,\dot g_2)$
cannot be forced by any
${\varphi }(\dot g_1,\dot g_2)$
cannot be forced by any
 $(p_1,p_2)$
because any two mutually generic
$(p_1,p_2)$
because any two mutually generic
 $g_1\succ p_1$
,
$g_1\succ p_1$
,
 $g_2\succ p_2$
are Turing incomparable and thus also
$g_2\succ p_2$
are Turing incomparable and thus also
 $g_1\not\!\! {\mathrel {E}} g_2$
. Similar to the proof of Theorem 21, we can find
$g_1\not\!\! {\mathrel {E}} g_2$
. Similar to the proof of Theorem 21, we can find
 $(p_1,p_2)$
such that
$(p_1,p_2)$
such that
 $(p_1,p_2)\Vdash \neg {\varphi }(\dot g_1,\dot g_2)$
. We again build recursive
$(p_1,p_2)\Vdash \neg {\varphi }(\dot g_1,\dot g_2)$
. We again build recursive
 $h_1\succ p_1$
and
$h_1\succ p_1$
and
 $h_2\succ p_2$
in stages with the added condition that
$h_2\succ p_2$
in stages with the added condition that
 $h_1$
and
$h_1$
and
 $h_2$
are infinite, coinfinite. Toward this let
$h_2$
are infinite, coinfinite. Toward this let
 $h^0_1=p_1$
and
$h^0_1=p_1$
and
 $h^0_2=p_2$
. Now suppose that we have defined
$h^0_2=p_2$
. Now suppose that we have defined
 $h^s_1$
and
$h^s_1$
and
 $h^s_2$
. If s is even, let
$h^s_2$
. If s is even, let
 $h^{s+1}_i=h^s_{i}{}^\smallfrown 01$
. If s is odd, let
$h^{s+1}_i=h^s_{i}{}^\smallfrown 01$
. If s is odd, let
 $h^{s+1}_i$
be the lexicographical minimal extension
$h^{s+1}_i$
be the lexicographical minimal extension
 $q_i$
of
$q_i$
of
 $h^s_i$
so that
$h^s_i$
so that
 $(q_1,q_2)\Vdash \exists n \neg R(\dot g_1, \dot g_2,s,n)$
. By the same argument as in the proof of Theorem 21 we can find such
$(q_1,q_2)\Vdash \exists n \neg R(\dot g_1, \dot g_2,s,n)$
. By the same argument as in the proof of Theorem 21 we can find such
 $(q_1,q_2)$
recursively.
$(q_1,q_2)$
recursively.
Odd stages ensure that the
 $h_i$
are characteristic functions of infinite, coinfinite sets and even stages ensure that
$h_i$
are characteristic functions of infinite, coinfinite sets and even stages ensure that
 $\neg {\varphi }(h_1,h_2)$
. However, as our construction is recursive, so are
$\neg {\varphi }(h_1,h_2)$
. However, as our construction is recursive, so are
 $h_1$
and
$h_1$
and
 $h_2$
and as two recursive infinite coinfinite sets are
$h_2$
and as two recursive infinite coinfinite sets are
 $1$
-equivalent,
$1$
-equivalent,
 $h_1\mathrel {E} h_2$
, contradicting that
$h_1\mathrel {E} h_2$
, contradicting that
 ${\varphi }$
defines E.
${\varphi }$
defines E.
Theorem 23 immediately implies that m-equivalence is not
 $\Pi ^0_3$
as it is a subequivalence relation of Turing equivalence that contains
$\Pi ^0_3$
as it is a subequivalence relation of Turing equivalence that contains
 $1$
-equivalence.
$1$
-equivalence.
The fact that we could assume that the relation R in the proof of Theorem 23 was recursive, allowed us to build recursive and infinite coinfinite reals, ensuring that they are
 $1$
-equivalent. Without this assumption, we cannot guarantee anymore that the elements built are both recursive, and thus our proof fails. In fact, if we allowed
$1$
-equivalent. Without this assumption, we cannot guarantee anymore that the elements built are both recursive, and thus our proof fails. In fact, if we allowed
 $\mathrm {TOT}=\{e:{\varphi }_e \text { total}\}$
as an oracle, then the definition of m-equivalence in Eq. (*) becomes
$\mathrm {TOT}=\{e:{\varphi }_e \text { total}\}$
as an oracle, then the definition of m-equivalence in Eq. (*) becomes
 $\Sigma ^0_2$
.
$\Sigma ^0_2$
.
Theorem 24. Both
 $\equiv _m$
and
$\equiv _m$
and
 $\equiv _1$
are
$\equiv _1$
are
 $\Sigma ^0_2(\mathrm {TOT})$
. Hence, they are learnable by a
$\Sigma ^0_2(\mathrm {TOT})$
. Hence, they are learnable by a
 $\mathrm {TOT}$
-computable learner.
$\mathrm {TOT}$
-computable learner.
4.2 Jump hierarchies
Let us recall the notion of a jump hierarchy. Roughly speaking, the Turing jump assigns to a set X its corresponding halting set
 $X'$
. This operation can be iterated to obtain “halting sets relative to halting sets”
$X'$
. This operation can be iterated to obtain “halting sets relative to halting sets”
 $X^{(n)}$
and so on—first, via finite iterations and then, via transfinite recursion. A jump hierarchy is a set that encodes in its columns a countable number of iterations of the Turing jump. In this way, any computable well-order gives rise to a jump hierarchy.
$X^{(n)}$
and so on—first, via finite iterations and then, via transfinite recursion. A jump hierarchy is a set that encodes in its columns a countable number of iterations of the Turing jump. In this way, any computable well-order gives rise to a jump hierarchy.
Definition 7. Given an infinite computable linear order
 $\prec $
on natural numbers let
$\prec $
on natural numbers let
 $[{\prec }n]=\{ m: m\prec n\}$
. A set
$[{\prec }n]=\{ m: m\prec n\}$
. A set
 $H\subseteq \omega $
is a jump hierarchy supported on
$H\subseteq \omega $
is a jump hierarchy supported on
 $\prec $
if
$\prec $
if
 $$\begin{align*}\forall n\in\omega\ H^{[n]}=(H^{[{\prec} n]})' \end{align*}$$
$$\begin{align*}\forall n\in\omega\ H^{[n]}=(H^{[{\prec} n]})' \end{align*}$$
where
 $H^{[n]}=\{m: \langle m,n\rangle \in H\}$
.
$H^{[n]}=\{m: \langle m,n\rangle \in H\}$
.
We can immediately observe that this definition is
 $\Pi ^0_2$
. If
$\Pi ^0_2$
. If
 $\alpha =(\omega ,\prec )$
is isomorphic to a computable ordinal, then the corresponding jump hierarchy is uniquely defined. In such cases, we abuse the notation and use
$\alpha =(\omega ,\prec )$
is isomorphic to a computable ordinal, then the corresponding jump hierarchy is uniquely defined. In such cases, we abuse the notation and use
 $\emptyset ^{(\alpha )}$
to denote the unique jump hierarchy supported on
$\emptyset ^{(\alpha )}$
to denote the unique jump hierarchy supported on
 $\prec $
. It is a well-known fact that if
$\prec $
. It is a well-known fact that if
 $\alpha $
is an infinite computable ordinal, then the corresponding jump hierarchy
$\alpha $
is an infinite computable ordinal, then the corresponding jump hierarchy
 $\emptyset ^{(\alpha +1)}$
is a
$\emptyset ^{(\alpha +1)}$
is a
 $\Sigma ^0_{\alpha }$
-complete set (see for example [Reference Montalbán17, Theorem V.16] or [Reference Ash and Knight1, p. 75]).
$\Sigma ^0_{\alpha }$
-complete set (see for example [Reference Montalbán17, Theorem V.16] or [Reference Ash and Knight1, p. 75]).
Jump hierarchies allow us to exemplify relatively simple, i.e., defined by a
 $\Pi ^0_2$
formula, equivalence relations, which are uniformly learnable but which require learners with computational power at arbitrarily high levels of the hyperarithmetic hierarchy. To this end, given a computable linear order
$\Pi ^0_2$
formula, equivalence relations, which are uniformly learnable but which require learners with computational power at arbitrarily high levels of the hyperarithmetic hierarchy. To this end, given a computable linear order
 $\prec $
and the corresponding
$\prec $
and the corresponding
 $\Pi ^0_2$
class
$\Pi ^0_2$
class
 $\mathbf {H}$
consisting of jump hierarchies supported on
$\mathbf {H}$
consisting of jump hierarchies supported on
 $\prec $
we define
$\prec $
we define
 $\equiv _{\prec }$
as follows.
$\equiv _{\prec }$
as follows.
 $$\begin{align*}x\equiv_\prec y \iff x=y\mbox{ or }x^{[1]}=y^{[1]}=z\in \mathbf{H} .\end{align*}$$
$$\begin{align*}x\equiv_\prec y \iff x=y\mbox{ or }x^{[1]}=y^{[1]}=z\in \mathbf{H} .\end{align*}$$
Proposition 25. Given a presentation
 $(\omega ,\prec )$
of an ordinal
$(\omega ,\prec )$
of an ordinal
 $\alpha $
, the equivalence relation
$\alpha $
, the equivalence relation
 $\equiv _{\prec }$
is uniformly learnable and for every z, if
$\equiv _{\prec }$
is uniformly learnable and for every z, if
 $\equiv _{\prec }$
is z-learnable, then
$\equiv _{\prec }$
is z-learnable, then
 $z\geq _T 0^{(\alpha )}$
.
$z\geq _T 0^{(\alpha )}$
.
Proof. First, since the jump hierarchy supported on
 $\prec $
is unique, it is straightforward to see that
$\prec $
is unique, it is straightforward to see that
 $\equiv _\prec $
is learnable. Now, using the definition of
$\equiv _\prec $
is learnable. Now, using the definition of
 $\equiv _{\prec }$
and our characterization of learnability (Theorem 6), we notice that
$\equiv _{\prec }$
and our characterization of learnability (Theorem 6), we notice that
 $x=\emptyset ^{(\alpha )}$
if and only if
$x=\emptyset ^{(\alpha )}$
if and only if
 $\emptyset \oplus x\equiv _{\prec }\omega \oplus x$
if and only if
$\emptyset \oplus x\equiv _{\prec }\omega \oplus x$
if and only if
 $\exists n\forall m {\varphi }(\emptyset \oplus x,\omega \oplus x,n,m)$
where
$\exists n\forall m {\varphi }(\emptyset \oplus x,\omega \oplus x,n,m)$
where
 ${\varphi }$
is
${\varphi }$
is
 $\Delta _1^0(z)$
and z computes a learner for
$\Delta _1^0(z)$
and z computes a learner for
 $\equiv _{\prec }$
. Fixing a witness n for
$\equiv _{\prec }$
. Fixing a witness n for
 ${\varphi }$
we obtain a
${\varphi }$
we obtain a
 $\Pi _1^0(z)$
definition of
$\Pi _1^0(z)$
definition of
 $\emptyset ^{(\alpha )}$
and therefore,
$\emptyset ^{(\alpha )}$
and therefore,
 $\emptyset ^{(\alpha )}$
is the unique path in a z-computable binary tree. Each isolated path in a z-computable binary tree is z-computable, hence z computes
$\emptyset ^{(\alpha )}$
is the unique path in a z-computable binary tree. Each isolated path in a z-computable binary tree is z-computable, hence z computes
 $\emptyset ^{(\alpha )}$
.
$\emptyset ^{(\alpha )}$
.
While the notion of jump hierarchy was originally defined with well-founded linear orders in mind—we start with the degree of computable functions and iterate the jump from there—a surprising consequence of the Gandy basis theorem is that there exist nonstandard jump hierarchies, supported on ill-founded linear orders. However, these are no longer unique. Indeed, Harrison [Reference Harrison9] noted that when an ill-founded linear order supports a jump hierarchy, then it supports a continuum many of them. Moreover, none of these non-standard jump hierarchies can be hyperarithmetic. Indeed, one can show that if a jump hierarchy contains an infinite descending sequence, then it must compute all hyperarithmetic reals. In fact, one can go further, and observe that if
 $\prec $
is ill-founded and supports a jump hierarchy, then no infinite
$\prec $
is ill-founded and supports a jump hierarchy, then no infinite
 $\prec $
-descending sequence is hyperarithmetic. Thus, we can make the following observation.
$\prec $
-descending sequence is hyperarithmetic. Thus, we can make the following observation.
Proposition 26. Given an ill-founded computable order
 $\prec $
, which supports a jump hierarchy, the equivalence relation
$\prec $
, which supports a jump hierarchy, the equivalence relation
 $\equiv _{\prec }$
is not uniformly learnable.
$\equiv _{\prec }$
is not uniformly learnable.
Proof. As in the proof of Proposition 25 we assume that z learns
 $\equiv _\prec $
and apply Theorem 6 to argue that there is a
$\equiv _\prec $
and apply Theorem 6 to argue that there is a
 $\Pi ^0_1(z)$
definition of some non-empty subset of the class of jump hierarchies supported on
$\Pi ^0_1(z)$
definition of some non-empty subset of the class of jump hierarchies supported on
 $\prec $
. Therefore, there exists a member of this class which is arithmetic in z—in fact, even
$\prec $
. Therefore, there exists a member of this class which is arithmetic in z—in fact, even
 $z'$
-computable. However, by Louveau’s separation theorem, z may be assumed to be hyperarithmetic, as
$z'$
-computable. However, by Louveau’s separation theorem, z may be assumed to be hyperarithmetic, as
 $\equiv _\prec $
is hyperarithmetic, in fact even
$\equiv _\prec $
is hyperarithmetic, in fact even
 $\Pi _2^0$
. This contradicts the fact that no jump hierarchy supported on an ill-founded order is hyperarithmetic.
$\Pi _2^0$
. This contradicts the fact that no jump hierarchy supported on an ill-founded order is hyperarithmetic.
One consequence of Proposition 26 is that for equivalence relations of the form
 $\equiv _\prec $
learnability identifies exactly the well-founded part of
$\equiv _\prec $
learnability identifies exactly the well-founded part of
 $\prec $
. More formally,
$\prec $
. More formally,
 $\equiv _{{\prec } n}$
is learnable if and only if
$\equiv _{{\prec } n}$
is learnable if and only if
 ${\prec } n$
is well-founded. This observation is closely connected to the following result, which is interesting in its own right.
${\prec } n$
is well-founded. This observation is closely connected to the following result, which is interesting in its own right.
Theorem 27. Let
 $\prec $
be an ill-founded computable order that supports a jump hierarchy. The well-founded part
$\prec $
be an ill-founded computable order that supports a jump hierarchy. The well-founded part
 $\mathcal {O}_\prec $
of
$\mathcal {O}_\prec $
of
 $\prec $
is
$\prec $
is
 $\Pi ^1_1$
but not
$\Pi ^1_1$
but not
 $\Sigma ^1_1$
and not
$\Sigma ^1_1$
and not
 $\Pi ^1_1$
-complete.
$\Pi ^1_1$
-complete.
Proof. The well-founded part of any computable linear order
 $\prec $
is clearly
$\prec $
is clearly
 $\Pi ^1_1$
as it is defined by
$\Pi ^1_1$
as it is defined by
 $$\begin{align*}n\in \mathcal O_{\prec} \iff (\forall \bar a \in [ {\prec}n ]^\omega) \exists i\ a_{i}\prec a_{i+1}\end{align*}$$
$$\begin{align*}n\in \mathcal O_{\prec} \iff (\forall \bar a \in [ {\prec}n ]^\omega) \exists i\ a_{i}\prec a_{i+1}\end{align*}$$
and
 $[{\prec } n]=\{m: m\prec n\}$
is uniformly computable. Since
$[{\prec } n]=\{m: m\prec n\}$
is uniformly computable. Since
 $\prec $
supports a jump hierarchy, it contains no infinite descending hyperarithmetic sequence. In particular,
$\prec $
supports a jump hierarchy, it contains no infinite descending hyperarithmetic sequence. In particular,
 $\overline {\mathcal {O}_\prec }$
cannot be hyperarithmetic, i.e.,
$\overline {\mathcal {O}_\prec }$
cannot be hyperarithmetic, i.e.,
 $\Delta ^1_1$
, and hence,
$\Delta ^1_1$
, and hence,
 $\mathcal {O}_\prec $
is not
$\mathcal {O}_\prec $
is not
 $\Delta ^1_1$
, which together with it being
$\Delta ^1_1$
, which together with it being
 $\Pi ^1_1$
implies that it is not
$\Pi ^1_1$
implies that it is not
 $\Sigma ^1_1$
.
$\Sigma ^1_1$
.
To see that
 $\mathcal {O}_\prec $
is not
$\mathcal {O}_\prec $
is not
 $\Pi ^1_1$
-complete suppose toward a contradiction that the
$\Pi ^1_1$
-complete suppose toward a contradiction that the
 $\Pi ^1_1$
-complete set
$\Pi ^1_1$
-complete set
 $\mathrm {WO}=\{e: {\varphi }_e \text { computes a diagram of a well-ordered set}\}$
reduces to
$\mathrm {WO}=\{e: {\varphi }_e \text { computes a diagram of a well-ordered set}\}$
reduces to
 $\mathcal {O}_\prec $
via a computable function computed by g. For simplicity, we assume that
$\mathcal {O}_\prec $
via a computable function computed by g. For simplicity, we assume that
 $\prec $
is a strict ordering. We use g to define a computable linear ordering
$\prec $
is a strict ordering. We use g to define a computable linear ordering
 $\leq _{a,b}$
uniformly for each pair of natural numbers a and b. The ordering is defined by induction—at each stage s,
$\leq _{a,b}$
uniformly for each pair of natural numbers a and b. The ordering is defined by induction—at each stage s,
 $\leq _{a,b}$
is a finite linear ordering of size s, starting from an empty ordering at
$\leq _{a,b}$
is a finite linear ordering of size s, starting from an empty ordering at
 $s=0$
. Suppose we have defined the ordering on the first s natural numbers and we are at stage
$s=0$
. Suppose we have defined the ordering on the first s natural numbers and we are at stage
 $s+1$
of the construction. If
$s+1$
of the construction. If
 $g_{s}(a)\prec g_{s}(b)$
, then we add
$g_{s}(a)\prec g_{s}(b)$
, then we add
 $s+1$
as the smallest element so far in
$s+1$
as the smallest element so far in
 $\leq _{a,b}$
. Otherwise, i.e., if
$\leq _{a,b}$
. Otherwise, i.e., if
 $g_{s}(b)\prec g_{s}(a)$
or one of the two computations did not halt after s steps, then we add s as the largest element so far in
$g_{s}(b)\prec g_{s}(a)$
or one of the two computations did not halt after s steps, then we add s as the largest element so far in
 $\leq _{a,b}$
. This finishes the construction.
$\leq _{a,b}$
. This finishes the construction.
Now, we use Smullyan’s double recursion theorem to argue that there exists
 $e_0$
and
$e_0$
and
 $e_1$
such that
$e_1$
such that
 ${\varphi }_{e_0}$
computes the diagram of
${\varphi }_{e_0}$
computes the diagram of
 $\leq _{e_0,e_1}$
and
$\leq _{e_0,e_1}$
and
 ${\varphi }_{e_1}$
computes the diagram of
${\varphi }_{e_1}$
computes the diagram of
 $\leq _{e_1,e_0}$
. Note that
$\leq _{e_1,e_0}$
. Note that
 $\leq _{e_0,e_1}$
is ill-founded if and only if
$\leq _{e_0,e_1}$
is ill-founded if and only if
 $\leq _{e_1,e_0}$
is well-founded. Suppose that
$\leq _{e_1,e_0}$
is well-founded. Suppose that
 $g(e_0)\prec g(e_1)$
. This means that
$g(e_0)\prec g(e_1)$
. This means that
 $\leq _{e_0,e_1}$
is ill-founded. However, by our assumption g is an appropriate reduction, and hence, g maps
$\leq _{e_0,e_1}$
is ill-founded. However, by our assumption g is an appropriate reduction, and hence, g maps
 $e_0$
outside of
$e_0$
outside of
 $\mathcal {O}_\prec $
. But since
$\mathcal {O}_\prec $
. But since
 $\leq _{e_1,e_0}$
is well-founded,
$\leq _{e_1,e_0}$
is well-founded,
 $g(e_1)\in \mathcal {O}_\prec $
. This is a contradiction, as the well-founded part of
$g(e_1)\in \mathcal {O}_\prec $
. This is a contradiction, as the well-founded part of
 $\prec $
is closed downwards. Similarly, we obtain a contradiction for the case when
$\prec $
is closed downwards. Similarly, we obtain a contradiction for the case when
 $g(e_1)\prec g(e_0)$
.
$g(e_1)\prec g(e_0)$
.
4.3 Model theory
As mentioned in the introduction, the work in this paper was inspired by the work of Fokina, Kötzing, and San Mauro [Reference Fokina, Kötzing and Mauro7] and others on learning the isomorphism relation on countably many isomorphism types. One of the first questions that arises is whether it is possible to learn the isomorphism relation on the whole space of structures. This should of course be impossible, as, in general, the isomorphism relation is not even Borel. The following proposition makes this observation precise in terms of non-uniform learnability.
Proposition 28. Let
 $\tau $
be a countable vocabulary containing at least one relation symbol. Then
$\tau $
be a countable vocabulary containing at least one relation symbol. Then
 $Mod(\tau )$
is not non-uniformly learnable.
$Mod(\tau )$
is not non-uniformly learnable.
Proof. We will assume without loss of generality that
 $\tau $
contains exactly one unary relation symbol R.
$\tau $
contains exactly one unary relation symbol R.
Consider structures
 $\mathcal {A}_n$
such that
$\mathcal {A}_n$
such that
 $R^{\mathcal {A}_n}(m)$
if and only if
$R^{\mathcal {A}_n}(m)$
if and only if
 $m\leq n$
, and a structure
$m\leq n$
, and a structure
 $\mathcal {A}_\infty $
where
$\mathcal {A}_\infty $
where
 $\{m: R^{\mathcal {A}_{\infty }}(m)\}$
is an infinite, coinfinite subset of A. Given
$\{m: R^{\mathcal {A}_{\infty }}(m)\}$
is an infinite, coinfinite subset of A. Given
 $x\in 2^\omega $
, let
$x\in 2^\omega $
, let
 $\mathcal {B}_x$
be such that
$\mathcal {B}_x$
be such that
 $R^{\mathcal {B}_x}(2n) \iff x(n)=1$
and
$R^{\mathcal {B}_x}(2n) \iff x(n)=1$
and
 $\neg R^{\mathcal {B}_x}(2n+1)$
for all n. Clearly, the map
$\neg R^{\mathcal {B}_x}(2n+1)$
for all n. Clearly, the map
 $x\mapsto \mathcal {B}_x$
is continuous and
$x\mapsto \mathcal {B}_x$
is continuous and
 $\mathcal {B}_x\cong \mathcal {A}_\infty $
if and only if
$\mathcal {B}_x\cong \mathcal {A}_\infty $
if and only if
 $x\in \mathrm {INF}$
.
$x\in \mathrm {INF}$
.
Now, assume there was a learner L for the sequence
 $(\mathcal {A}_\infty ,\mathcal {A}_1,\dots )$
, i.e., there are
$(\mathcal {A}_\infty ,\mathcal {A}_1,\dots )$
, i.e., there are
 $\boldsymbol {\Sigma }^0_2$
sets separating the isomorphism classes. Then, we would get that
$\boldsymbol {\Sigma }^0_2$
sets separating the isomorphism classes. Then, we would get that
 $x\in \mathrm {INF}$
if and only if
$x\in \mathrm {INF}$
if and only if
 $\mathcal {B}_x\in S$
where S is the
$\mathcal {B}_x\in S$
where S is the
 $\boldsymbol {\Sigma }^0_2$
set containing
$\boldsymbol {\Sigma }^0_2$
set containing
 $Iso(\mathcal {A}_\infty )$
. But then
$Iso(\mathcal {A}_\infty )$
. But then
 $\mathrm {INF}$
would be
$\mathrm {INF}$
would be
 $\boldsymbol {\Sigma }^0_2$
, contradicting that
$\boldsymbol {\Sigma }^0_2$
, contradicting that
 $\mathrm {INF}$
is
$\mathrm {INF}$
is
 $\boldsymbol {\Pi }^0_2$
-complete.
$\boldsymbol {\Pi }^0_2$
-complete.
Remark. Various examples of countable classes of structures C that are explanatory learnable are known [Reference Bazhenov, Fokina and Mauro3]. Thus, Proposition 28 fails if we restrict our attention to
 $\tau $
-structures satisfying a fixed
$\tau $
-structures satisfying a fixed
 $L_{\omega _1\omega }$
sentence
$L_{\omega _1\omega }$
sentence
 ${\varphi }$
.
${\varphi }$
.
The following is an immediate corollary of Propositions 28 and 1. It generalizes the result by Miller that no structure in relational language has a
 $\Sigma ^{\mathrm {in}}_{2}$
Scott sentence [Reference Miller16].
$\Sigma ^{\mathrm {in}}_{2}$
Scott sentence [Reference Miller16].
Corollary 29. There is no vocabulary
 $\tau $
such that for all
$\tau $
such that for all
 $\mathcal {A}_0,\dots \in Mod(\tau )$
there are
$\mathcal {A}_0,\dots \in Mod(\tau )$
there are
 $\boldsymbol {\Sigma }^0_2$
sets
$\boldsymbol {\Sigma }^0_2$
sets
 $(S_i)_{i\in \omega }$
such that
$(S_i)_{i\in \omega }$
such that
 $\mathcal {A}_i\subseteq S_i$
and
$\mathcal {A}_i\subseteq S_i$
and
 $S_i\cap S_j=\emptyset $
if and only if
$S_i\cap S_j=\emptyset $
if and only if
 $\mathcal {A}_i\not \cong \mathcal {A}_j$
.
$\mathcal {A}_i\not \cong \mathcal {A}_j$
.
If we consider Borel learnability, then the picture becomes a bit more interesting. Hjorth and Kechris [Reference Hjorth and Kechris10] showed that an equivalence relation induced by the Borel action of a closed subgroup of
 $S_{\infty }$
, the permutation group of the natural numbers, is potentially
$S_{\infty }$
, the permutation group of the natural numbers, is potentially
 $\boldsymbol {\Sigma }^0_2$
if and only if it is essentially countable, i.e., Borel reducible to a countable equivalence relation. Since the isomorphism relation on any class of structures is an orbit equivalence relation induced by
$\boldsymbol {\Sigma }^0_2$
if and only if it is essentially countable, i.e., Borel reducible to a countable equivalence relation. Since the isomorphism relation on any class of structures is an orbit equivalence relation induced by
 $S_{\infty }$
we get the following as a corollary of Theorem 13.
$S_{\infty }$
we get the following as a corollary of Theorem 13.
Corollary 30. Given an
 $L_{\omega _1\omega }$
sentence
$L_{\omega _1\omega }$
sentence
 ${\varphi }$
we have that
${\varphi }$
we have that
 $\cong _{\varphi }$
is Borel learnable if and only if
$\cong _{\varphi }$
is Borel learnable if and only if
 $\cong _{\varphi }$
is essentially countable.
$\cong _{\varphi }$
is essentially countable.
Acknowledgments
Part of this research was conducted when the first and the last author were visiting University of California, Berkeley, where the middle author resides.
Funding
The work of Rossegger was supported by the European Union’s Horizon 2020 Research and Innovation Programme under the Marie Skłodowska-Curie grant agreement No. 101026834 — ACOSE. Steifer was supported by the National Science Center grant no. 2021/05/X/ST6/00594 and by the Agencia Nacional de Investigación y Desarrollo grant no. 3230203.



 Open access
Open access